<Python数据科学手册>笔记
 times read
times read
Contents
数据科学概念
它综合了三个领域的能力
- 统计学家 : 建立模型和聚合数据
- 计算机科学家 : 设计并使用算法对数据进行高效存储, 分析和可视化
- 领域专家 : 有细分领域中经过专业训练, 既可提出正确的问题, 又可作出专业的解答
环境
https://www.anaconda.com/distribution/#download-section
https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
conda install numpy pandas scikit-learn matplotlib seaborn ipython-notebook
jupyter /ipython
ipython
jupyter notebook
方便
Jupyter
在 Jupyter 查看帮助文档
?: 比如len?或对象.方法名???: 获取源码. 例如square??<TAB>: 自动补全- 通配:
str.*find*?或*Warning?
ipython
%paste 或 %cpaste: 从粘贴板里粘贴代码块并排版%run: 执行外部代码. 例如%run myscript.py- 代码耗时
%time: 对单个语句执进行计时%timeit: 对单个语句重复执行进行计时%%timeit: 计算多行代码的耗时%prun: 利用分析器运行代码. 例如%prun sum_of_lists(1000000)%lprun: 利用逐行分析器运行代码. 要安装扩展pip install line_profiler, 然后导入 %load_ext line_profiler%memit: 测量单个语句的内存使用. 要安装扩展pip install memory_profiler, 然后导入 %load_ext memory_profiler%mprun: 通逐行的内存分析器运行代码. 扩展同上.
%magic: 查看 magic 函数的使用%lsmagic: 查看所有 magic 相关的函数In 和 OUT 对象:print(In), 引用相应的对象In[N]- OUT 对象不包括 None 的输出
- 禁止输出. 在语句后面添加分号
;
%history -n 1-4: 列出历史第 1到 4 条命令!ls: 执行外部命令lscontents = !ls: 保存外部命令的输出%xmode Verbose: 控制异常信息%debug: 调试
NumPy
理解动态类型
Python 中的整型不仅仅是一个整型, 标准的 Python 实现是用 C 语言编写的. 这意味着每一个 Python 对象都是一个聪明的伪 C 语言结构体, 该结构体不仅包含其值, 还有其他信息. 例如 Python 中 long 的定义如下
struct _longobject {
long ob_refcnt;
PyTypeObject *ob_type;
size_t ob_size;
long ob_digit[1];
};
分别为
- 引用计数
- 类型编码
- 对象大小
- 实际值
即 Python 对象的 ObjectHeader
Python 中的列表元素也是, 可以不相同的类型
固定元素类型 array/ndarray
Python 3.3 之后
import array
L = list(range(10))
A = array.array('i', L)
'i': 表示类型码, 这里为整型
也可以用 NumPy 的 ndarray
ndarray 可以显式指定元素类型: np.array([1,2,3], dtype='float32')
numpy 初始化数组
np.zeros(10, dtype=int)
# 3*5 (3行, 5列)
np.ones((3,5), dtype=float)
# 3行 5列, 每个元素都初始化为 3.14
np.full((3,5), 3.14)
# 5 个元素, 均匀地分配到范围 0~1
np.linspace(0, 1, 5)
# 3*3 , 每个元素为 0~1 的随机数
np.random.random((3,3))
# 3*3, 均值为 0, 标准差为 1 的正态分布的随机数组
np.random.normal(0, 1, (3,3))
# 3*3, [0, 10) 区间的随机整型数组
np.random.randint(0, 10, (3, 3))
# 单位矩阵, 3*3
np.eye(3)
# 3 个整数组成的数组, 元素是当前内存中的任意值
np.empty(3)
NumPy 的属性
ndim: 数组的维度shape: 数组每个维度的大小size: 数组的总大小. 每个维度的大小的乘积.dtype: 元素类型itemsize: 元素字节大小nbytes: 数组总字节大小. 一般可认为itemsize * size
索引从 0 开始
索引 -1 表示最后一个元素
多维数组中, 可用逗号分隔的索引元组来索引. 例如 [1, 5]
数组切片
x[start:stop:step], 要特别注意的是它返回的是数据的视图, 而不是数据的副本. 而在 python 列表中, 切片是副本.
x[:5]: 前 5 个元素x[5:]: 后 5 个元素x[4:7]: 中间子元素x[::2]: 每隔一个元素x[::-1]: 逆序元素x[5::-2]: 从索引 5 开始, 每隔一个元素逆序
多维切片同理, 在每个维度中, 采用上面类似的处理, 用逗号分隔
x2[:3, :2]: 三行, 两列
获取数组的行和列
x2[:, 0]: x2 的第一列x2[0, :]: x2 的第一行, 更简的写法为x2[0]
创建副本: copy 方法
x2[:2, :2].copy()
数组的变形
reshape() 方法
grid = np.arange(1, 10).reshape((3,3))
print(grid)
数组的拼接
np.concatenate: 例如 .np.concatenate([x, y]), 其中 x=[1,2,3], y=[3,2,1]np.vstack: 垂直栈拼接np.hstack: 水平栈拼接
数组的分裂
np.split:np.split(要分裂的数组, 分裂点)np.split(x, [N])表示分裂为x[0:N], x[N:]np.split(x, [N,M])表示分裂为x[0:N], x[N:M], x[M:]
np.hsplit: 即按列分割np.vsplit: 即按行分割
通用函数
NumPy 快的关键是利用 向量化 操作, 这通常在 NumPy 的 ufunc (通用函数) 中实现.
scipy.special 模块也提供了类似的通用函数. 它提供更丰富的数学函数
x=np.range(4)
theta = np.linspace(0, np.pi, 3)
- 数组的运算: 如
x + 5 - 绝对值.
np.abs(x) - 三角函数:
np.sin(theta) - 指数和对数:
np.exp(x), np.exp2(x), np.power(3, x) - 专用通用函数.
scipy.special模块.from scipy import special
高级通用函数
指定输出. 所有的通用函数都可以通过out参数来指定计算结果的存放位置聚合.reduce一个数组, 它会对给定的元素和操作重复执行, 直到得到单个结果. 如np.add.reduce(x)外积. 对两个输入数组所有元素对应函数运算结果. 如np.multiply.outer(x, x)
聚合
- 求和
sum(x)或np.sum(x)(这个更好) - 最大/最小值:
min(x), max(x)或np.min(x), np.max(x)或x.min(), x.max(), x.sum()
多维度聚合
x.min(axis=0)
通过 axis 参数来指定维度. 默认情况下是所有.
聚合函数
| 函数 | NaN 安全版本 | 描述 |
|---|---|---|
np.sum |
np.nansum |
元素求和 |
np.prod |
np.nanprod |
元素的积 |
np.mean |
np.nanmean |
元素的平均值 |
np.std |
np.nanstd |
元素的标准差 |
np.var |
np.nanvar |
元素的方差 |
np.min |
np.nanmin |
元素最小值 |
np.max |
np.nanmax |
元素的最大值 |
np.argmin |
np.nanargmin |
元素最小值的索引 |
np.argmax |
np.nanargmax |
元素最大值的索引 |
np.median |
np.nanmedian |
元素的中位数 |
np.percentile |
np.nanpercentile |
基于元素排序的统计值 |
np.any |
没有 | 元素是否存在为真 |
np.all |
没有 | 所有元素是否为真 |
广播
用于不同大小数组的二元通用函数的一组规则
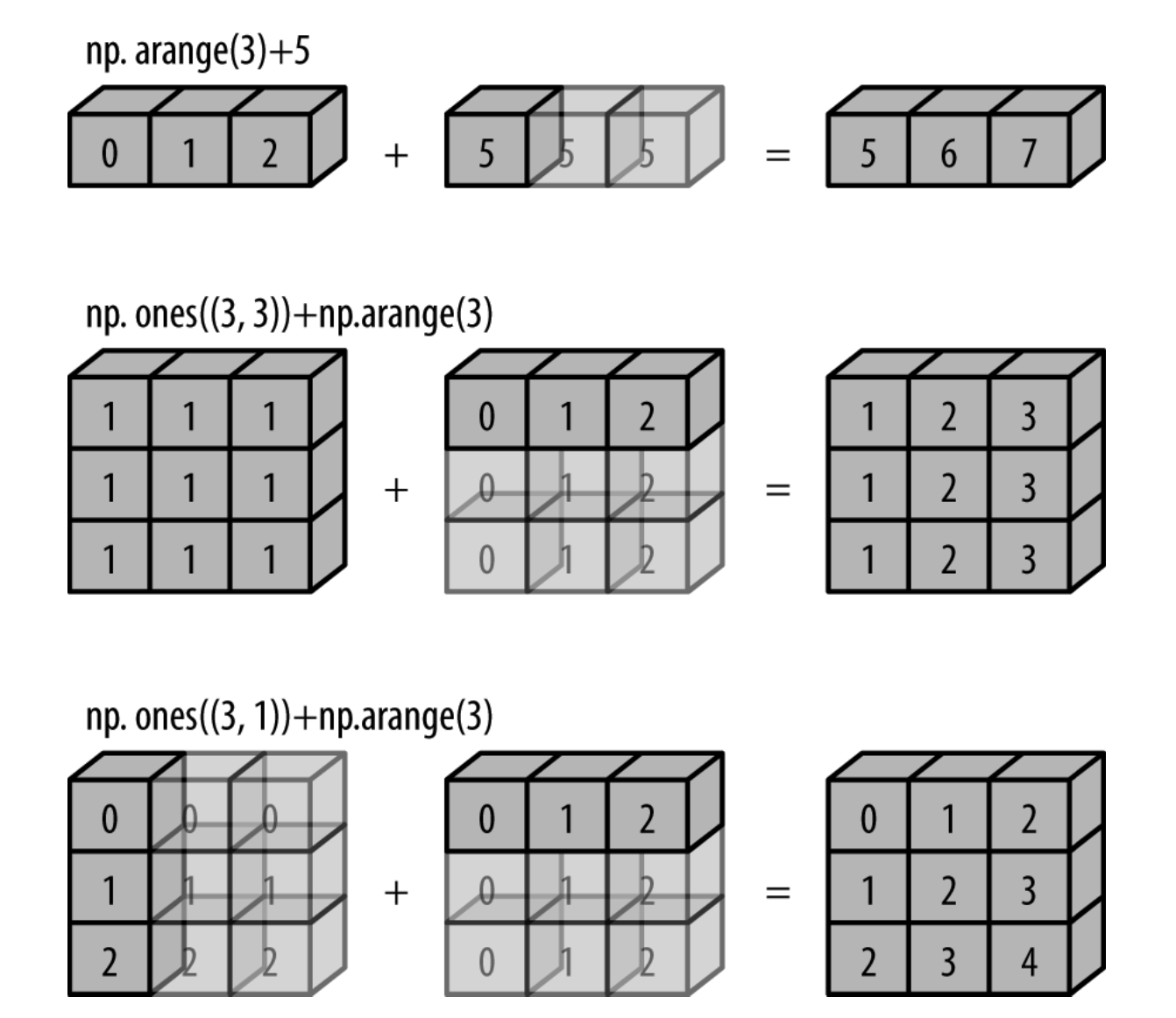
规则
- 如果两个数组的维度数不相同, 那么小的维度数组的形状将会在最左边补 1
- 如果两个数组的形状在任何一个维度上都不匹配, 那么数组的形状会沿着维度为 1 的维度扩展以匹配另外一个数组的形状
- 如果两个数组的形状在任何一个维度上都不匹配并且没有任何一个维度等于 1, 那么会引发异常
实际应用
归一化
X = np.random.random((10, 3))
Xmean = X.mean(0)
X_centered = X - Xmean
画一个二维函数
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 5, 50)
y = np.linspace(0, 5, 50)[:, np.newaxis]
z = np.sin(x) ** 10 + np.cos(10 + y*x) * np.cos(x)
plt.imshow(z, origin='lower', extent=[0, 5, 0, 5], cmap='viridis')
plt.colorbar()
比较通用函数
| 运算 | 对应通用函数 |
|---|---|
== |
np.equal |
!= |
np.not_equal |
< |
np.less |
<= |
np.less_equal |
> |
np.greater |
>= |
np.greater_equal |
rng = np.random.RandomState(0)
x = rng.randint(10, size=(3, 4))
x < 6
操作布尔数组
x = [[5 0 3 3]
[7 9 3 5]
[2 4 7 6]]
- 统计个数:
np.count_nonzero(x < 6)或np.sum(x<6)(False 为 0, True 为 1) - 检查是否存在:
np.any(x>8)表示有没有大于 8 的值 - 检查所有:
np.all(x < 8, axis=0)表示0 维度的所有元素是否都小于 8. 不写维度表示所有
布尔运算
&: 位与|: 位或^: 异或~: 取反rng = np.random.RandomState(0) x = rng.randint(10, size=(3, 4)) print("大于 0 的个数", np.sum(x > 0)) print("等于 0 的个数", np.sum(x == 0)) print("大于 5 的个数", np.sum(x > 5)) print("大于 5 且小于 8 的个数", np.sum((x > 5) & (x < 8)) )
掩码
选择器
rng = np.random.RandomState(0)
x = rng.randint(10, size=(3, 4))
# 即将 x 各个元素小于 5 的筛选出来
x[x < 5]
索引
x[0]x[:5]x[x<5]fancy indexing: 它传递的是索引数组, 而不是单个标量.结果是索引数组的形状. 它返回的值反映的是广播后的索引数组的形状x = [51 92 14 71 60 20 82 86 74 74] ind = [3, 7, 4] x[ind] # 修改 x[ind] = 99
排序
np.sort: 快速排序- 对每一行排序:
np.sort(x, axis=1) - 对每一列排序:
np.sort(x, axis=0) - 注意, 上面是分别排序, 任何行或列之间的关系将丢失!
- 对每一行排序:
np.argsort: 它返回的是原始数组排好序的索引值- 分隔:
np.partition(x, k): 返回一个新的数组, 最左边是第 K 小的值, 右边是任意顺序的其他元素. 两个部分都是任意排序的!
结构化数组
name = ['Alice', 'Bob', 'Cathy', 'Doug']
age = [25, 45, 37, 19]
weight = [55.0, 85.5, 68.0, 61.5]
data = np.zeros(4, dtype={'names':('name', 'age', 'weight'),
'formats':('U10', 'i4', 'f8')})
data['name'] = name
data['age'] = age
data['weight'] = weight
print(data)
# 获取年龄小于30岁的人的名字
data[data['age'] < 30]['name']
数据类型
格式为
- 第一个可选字符是
<(低字节序)或>(高字节序) - 第二个是数据的类型
'b': 字节'i': 有符号整型'u': 无符号整型'f': 浮点型'c': 复数浮点型'S', 'a': 字符串'U': Unicode 编码字符串'V': 原生数据
- 最后一个字符表示该对象的字节大小
dtype([('name', '<U10'), ('age', '<i8'), ('weight', '<f4')])
复合类型
用 mat 来表示矩阵
tp = np.dtype([('id', 'i8'), ('mat', 'f8', (3, 3))])
X = np.zeros(1, dtype=tp)
print(X[0])
Pandas
DataFrame 本质上是一种带行标签和列标签, 支持相同类型数据和缺失值的多维数组
基本数据结构
Series
一个带索引数据构成的一维数组
data = pd.Series([0.25, 0.5, 0.75, 1.0])
data
输出为
0 0.25
1 0.50
2 0.75
3 1.00
dtype: float64
属性
valuesindex
显式指定索引
data = pd.Series([0.25, 0.5, 0.75, 1.0], index=['a', 'b', 'c', 'd'])
data
data['b']
# 不连续的也可以
data = pd.Series([0.25, 0.5, 0.75, 1.0], index=[2, 5, 3, 7])
data[5]
Series 是特殊的字典
用 python 内置的字典秋创建 Series 对象时, 其索引默认按顺序排列.
population_dict = {'California': 38332521, 'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
population
# 输出为
California 38332521
Texas 26448193
New York 19651127
Florida 19552860
Illinois 12882135
dtype: int64
# 获取数据
population['California']
# 也可使用切片
population['California':'Illinois']
DataFrame
可作用一个通用型 NumPy 数组, 也可以看作特殊的 Python 字典
如果 Series 是灵活的一维数组, 那可以将 DataFrame 看作灵活的二维数组
population_dict = {'California': 38332521, 'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
area_dict = {'California': 423967, 'Texas': 695662, 'New York': 141297,
'Florida': 170312, 'Illinois': 149995}
area = pd.Series(area_dict)
states = pd.DataFrame({'population': population, 'area': area})
states
输出为
population area
California 38332521 423967
Texas 26448193 695662
New York 19651127 141297
Florida 19552860 170312
Illinois 12882135 149995
属性
indexcolumns
创建 DataFrame 对象
# 通过 Series 创建
pd.DataFrame(population, columns=['population'])
# 通过字典创建
data = [{'a': i, 'b': 2 * i} for i in range(3)]
pd.DataFrame(data)
# 通过 series 对象创建
states = pd.DataFrame({'population': population, 'area': area})
# 通过 NumPy 二维数组创建
pd.DataFrame(np.random.rand(3, 2), columns=['foo', 'bar'], index=['a', 'b', 'c'])
# 通过 NumPy 结构化数组创建
A = np.zeros(3, dtype=[('A', 'i8'), ('B', 'f8')])
pd.DataFrame(A)
Index
可以将它看作是一个不可变数组 或 有序集合(实际是一个多集 ,Index 对象可能包含重复值)
不可变数组
不可以 ind[0] = newValue
ind = pd.Index([2, 3, 5, 7, 11])
# 它还有许多属性
print(ind.size, ind.shape, ind.ndim, ind.dtype)
看成有序集合
indA = pd.Index([1, 3, 5, 7, 9])
indB = pd.Index([2, 3, 5, 7, 11])
# 交集
indA & indB
# 并集
indA | indB
# 异或
indA ^ indB
对象数据选择
Series
import pandas as pd
data = pd.Series([0.25, 0.5, 0.75, 1.0],index=['a', 'b', 'c', 'd'])
data
# 看作字典
data['a']
'a' in data
data.keys()
list(data.items())
# 添加数据
data['e'] = 1.25
# 看作一维数组
data['a':'c']
data[0:2]
# 掩码
data[ (data > 0.3) & (data < 0.8) )
# fancy index
data[['a', 'e']]
data = pd.Series([‘a’, ‘b’, ‘c’], index=[1, 3, 5])
整数索引容易混乱.
data[1] 会使用显式索引
而
data[1:3] 会使用隐式索引
可通过索引器来为显式指定
# 结果为 a
data.loc[1]
python 形式的隐式指定
# 结果为 b
data.iloc[1]
DataFrame
area = pd.Series({'California': 423967, 'Texas': 695662, 'New York': 141297, 'Florida': 170312,
'Illinois': 149995})
pop = pd.Series({'California': 38332521, 'Texas': 26448193,
'New York': 19651127, 'Florida': 19552860,
'Illinois': 12882135})
data = pd.DataFrame({'area':area, 'pop':pop})
# 看作字典, 下面两个都可以
data['area']
# 纯字符串的才可以, 建议少数这种, 避免冲突
data.area
# 增加一列
data['density'] = data['pop'] / data['area']
# 看作二维数组
data.values
# 进行转置
data.T
# 获取一行数据
data.values[0]
# 获取某列
data['area']
# python 隐式索引获取数据
data.iloc[:3, :2]
data.loc[:'Illinois', :'pop']
# 混合上面两种
data.ix[:3, :'pop']
# fancy index
data.loc[data.density > 100, ['pop', 'density']]
# 过虑行
data[data.density > 100]
# 如果 index 是日期类型
data['2010-01-01':'2010-02-01']
运算
对于一元运算, 它会在输出结果中保留索引和列标签
对于二元运算, 在传递通用函数时会自动对齐索引进行计算
索引对齐
Series 索引对齐
area = pd.Series({'Alaska': 1723337, 'Texas': 695662, 'California': 423967}, name='area')
population = pd.Series({'California': 38332521, 'Texas': 26448193, 'New York': 19651127}, name='population')
population / area
结果数组的索引是两个输入数组索引的并集 . 缺失值用 NaN 来填充. 也可以指定缺失值
A.add(B, fill_value=0)
DataFrame 索引对齐
A = pd.DataFrame(rng.randint(0, 20, (2, 2)),columns=list('AB'))
B = pd.DataFrame(rng.randint(0, 10, (3, 3)),columns=list('BAC'))
A + B
# 指定缺失值
fill = A.stack().mean()
A.add(B, fill_value=fill)
DataFrame 与 Series 运算
这与二维数组与一维数组的运算规则一样
缺失值
None: 它是一个 Python 对象, 所以不能作为任何 NumPy / Pandas 数组类型的缺失值, 只能用于object数组类型NaN: 数值类型的缺失值. 无论与 NaN 进行何种操作, 最终结果都是 NaN. 用np.nan表示.它是一种特殊的浮点数
Pandas 中是把它们看成等价交换的
处理缺失值
isnull(): 创建一个布尔类型的掩码标签缺失值notnull(): 与 isnull 操作相反dropna(): 返回一个剔除缺失值的数据- 对于 DataFrame , 要么是剔除缺失值所在的整行, 要么是整列.
默认是剔除整行数据 df.dropna(axis='columns'): 剔除任何包含缺失值的整列数据df.dropna(axis='rows', thresh=3)thresh:非缺失值的最小数量. 即该行中非缺失值的数量>=3就保留
- 对于 DataFrame , 要么是剔除缺失值所在的整行, 要么是整列.
fillna(): 返回一个填充了缺失值的数据副本data.fillna(method='ffill'): 用缺失值前面的有效值来从前往后填充forward-filldata.fillna(method='bfill'): 用缺失值后面的有效值来从后往前填充back-fillDataFrame 类似
df.fillna(method='ffill', axis=1). 只是在填充时设置坐标轴参数 axisdata = pd.Series([1, np.nan, 'hello', None]) data.isnull() data[data.notnull()]
多级索引 Series
笨办法
index = [('California', 2000), ('California', 2010),
('New York', 2000), ('New York', 2010),
('Texas', 2000), ('Texas', 2010)]
populations = [33871648, 37253956,
18976457, 19378102,
20851820, 25145561]
pop = pd.Series(populations, index=index)
pop[('California', 2010):('Texas', 2000)]
pop[[i for i in pop.index if i[1] == 2010]]
Pandas 多级索引
index = pd.MultiIndex.from_tuples(index)
# 笨办法上面的 pop
pop = pop.reindex(index)
# 输出结果为
California 2000 33871648
2010 37253956
New York 2000 18976457
2010 19378102
Texas 2000 20851820
2010 25145561
dtype: int64
# 等同笨办法的
# pop[[i for i in pop.index if i[1] == 2010]]
pop[:, 2010]
将一个多级索引的 Series 转化为普通索引的 DataFrame
pop_df = pop.unstack()
# 再转回多级索引
new_pop = pop_df.stack()
可以利用多级索引来表示任意维度的数据
多级索引的创建
最直接的办法是将 index 参数设置为至少二维的索引数组
df = pd.DataFrame(np.random.rand(4, 2), index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],columns=['data1', 'data2'])
df
结果为
data1 data2
a 1 0.511362 0.973176
2 0.079617 0.493073
b 1 0.623067 0.475468
2 0.246864 0.120539
通过字典来创建
data = {('California', 2000): 33871648,
('California', 2010): 37253956,
('Texas', 2000): 20851820,
('Texas', 2010): 25145561,
('New York', 2000): 18976457,
('New York', 2010): 19378102}
pd.Series(data)
多级索引的等级名
pop.index.names = ['state', 'year']
多级列索引
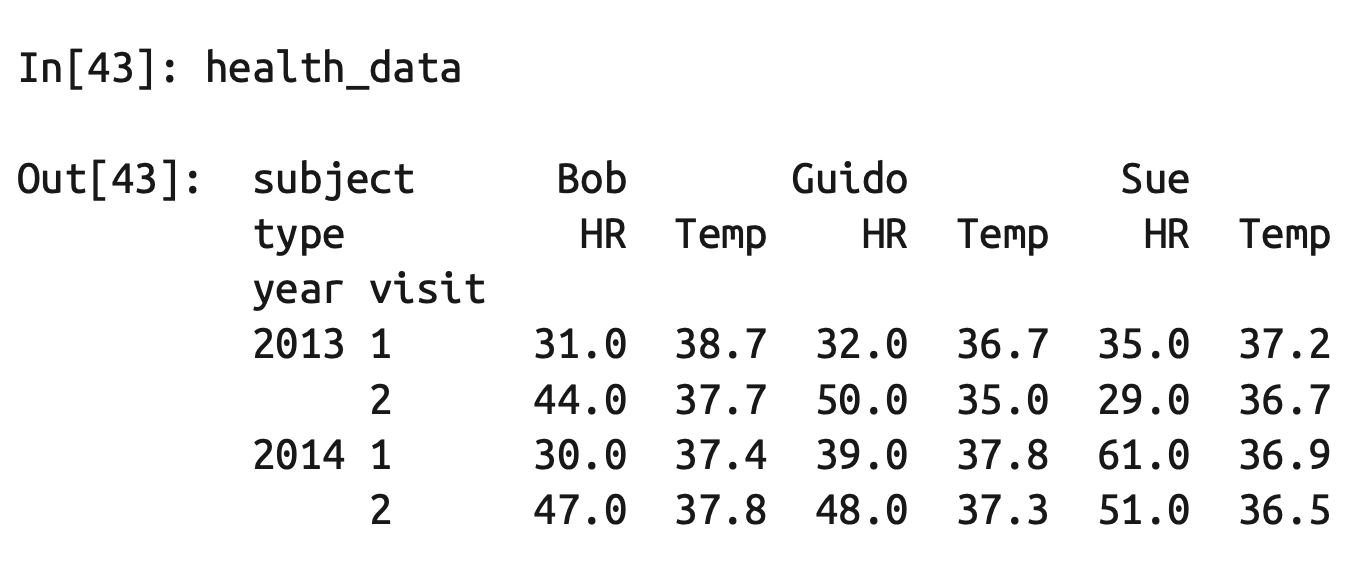
# 多级行列索引
index = pd.MultiIndex.from_product([[2013, 2014], [1, 2]],
names=['year', 'visit'])
columns = pd.MultiIndex.from_product([['Bob', 'Guido', 'Sue'], ['HR', 'Temp']],
names=['subject', 'type'])
# 模拟数据
data = np.round(np.random.randn(4, 6), 1)
data[:, ::2] *= 10
data += 37
# 创建DataFrame
health_data = pd.DataFrame(data, index=index, columns=columns)
health_data
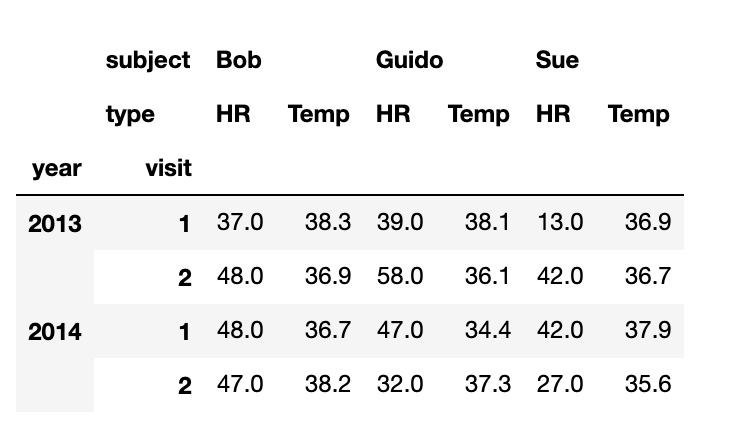
多级索引的取值与切片
Series
index = [('California', 2000), ('California', 2010),
('New York', 2000), ('New York', 2010),
('Texas', 2000), ('Texas', 2010)]
populations = [33871648, 37253956,
18976457, 19378102,
20851820, 25145561]
pop = pd.Series(populations, index=index)
index = pd.MultiIndex.from_tuples(index)
pop = pop.reindex(index)
pop.index.names=['state', 'year']
pop
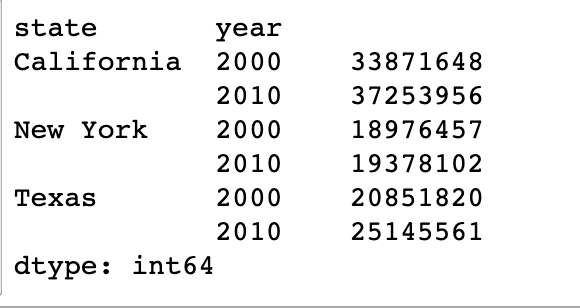
# 获取单个元素
pop['California', 2000]
# 获取局部
pop['California']
# 切片
pop.loc['California':'New York']
pop[:, 2000]
# 过虑
pop[pop > 22000000]
# fancy index
pop[['California', 'Texas']]
DataFrame
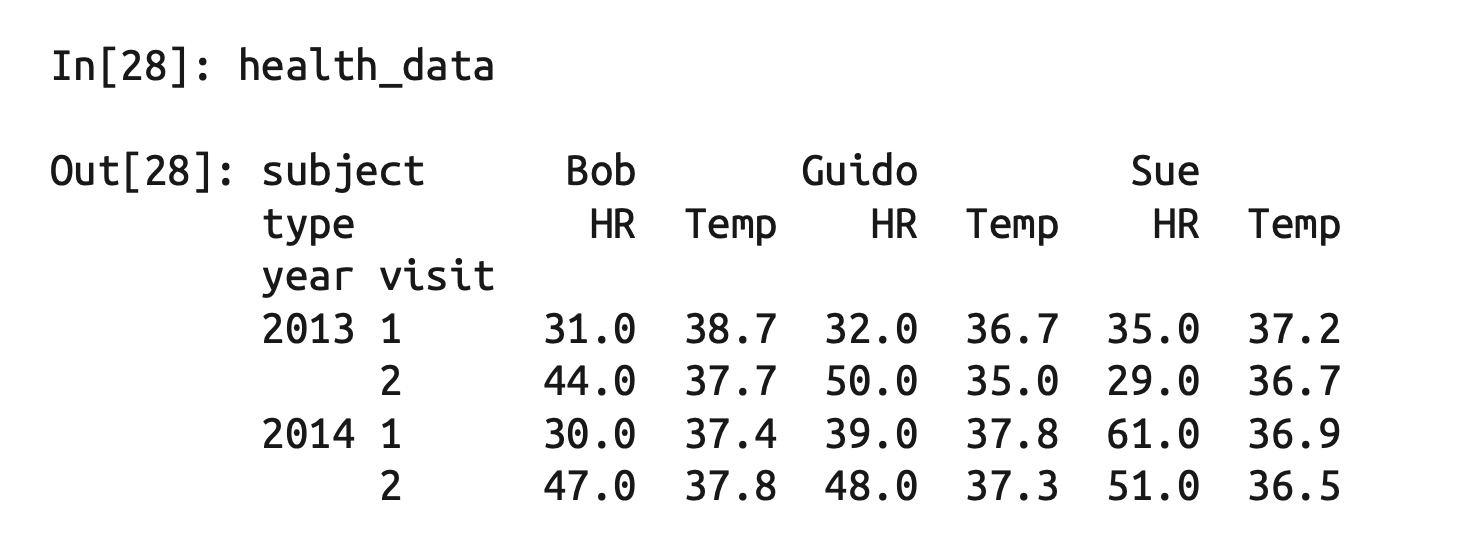
health_data['Guido', 'HR']
health_data.iloc[:2, :2]
health_data.loc[:, ('Bob', 'HR')]
多级索引其他
索引排序
切片最好要索引有序的
data = data.sort_index()
# 之后切片
data['a':'b']
索引 stack 与 unstack
将多级索引数据转换为二维形式
pop.unstack(level=0)
pop.unstack(level=1)
stack 是 unstack 的逆操作
索引的设置与重置
pop_flat.set_index(['state','year'])
pop_flat = pop.reset_index(name='population')
多级索引的数据统计方法
data_mean = health_data.mean(level='year')
data_mean.mean(axis=1, level='type')
concat 与 append
默认情况下 concat 是按行的
ser1 = pd.Series(['A', 'B', 'C'], index=[1, 2, 3])
ser2 = pd.Series(['D', 'E', 'F'], index=[4, 5, 6])
pd.concat([ser1, ser2])
输出为
1 A
2 B
3 C
4 D
5 E
6 F
dtype: object
按列 concat
pd.concat([df3, df4], axis='col')
索引重复
如果想检测是否有重复, 有的话检查异常
try:
pd.concat([x, y], verify_integrity=True)
except ValueError as e:
print("ValueError:", e)
忽略索引
# 如果将参数设置为 True,那么合并时将会创建一个新的整数索引
pd.concat([x, y], ignore_index=True)
增加多级索引
pd.concat([x, y], keys=['x', 'y'])
类似 join 合并
# 相同的列名才合并
pd.concat([df5, df6], join='inner')
# 指定列名合并
pd.concat([df5, df6], join_axes=[df5.columns])
append 方法
df1.append(df2)
join 与 merge
提供类似数据库的操作
merge
pd.merge() 实现了三种数据连接类型
- 一对一
- 多对一
多对多
# merge 会自动判断 df1, df2 中相同的列名(不一定要求顺序), 然后以该相同的列进行 merge df3 = pd.merge(df1, df2)
指定合并键
# df1, df2 有相同的列名才可用
pd.merge(df1, df2, on='employee')
# df1 使用 employee, df2 使用 name 来进行 merge
pd.merge(df1, df3, left_on="employee", right_on="name")
# 删除多余列
pd.merge(df1, df3, left_on="employee", right_on="name").drop('name', axis=1)
合并索引
pd.merge(df1a, df2a, left_index=True, right_index=True)
join
它是按照索引进行数据合并
df1a.join(df2a)
# 指定索引名
pd.merge(df1a, df3, left_index=True, right_on='name')
合并规则
# 内联. 这是默认行为
pd.merge(df6, df7, how='inner')
how 可支持
inner: 默认. 交集'outer': 并集. 缺失值用 NaN 填充'left': 左连接, 表示结果只包含左列'right': 右连接, 表示结果只包含右列
重名列
pd.merge() 会自动加后缀. 也可指定
pd.merge(df8, df9, on="name", suffixes=["_L", "_R"])
数据累计
# Series
rng = np.random.RandomState(42)
ser = pd.Series(rng.rand(5))
ser.sum()
ser.mean()
# DataFrame. 累计函数默认对每列进行统计
df = pd.DataFrame({'A': rng.rand(5), 'B': rng.rand(5)})
df.mean()
# 对每一行进行统计
df.mean(axis='columns')
# 计算每一列的若干常用统计值
df.dropna().describe()
Pandas 内置统计方法.
count()first()last()mean()median()min()max()std(): 标准差var: 方差mad(): 均值绝对偏差prod(): 所有项乘积sum(): 所有项求和
groupBy
它会进行: 分割(split) -> 应用(apply) -> 组合(combine)
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data': range(6)}, columns=['key', 'data'])
df.groupby('key').sum()
其他示例planets.groupby('method')['orbital_period'].median()
按组迭代
for (method, group) in planets.groupby('method'):
print("{0:30s} shape={1}".format(method, group.shape))
调用方法
planets.groupby('method')['year'].describe().unstack()
aggregate, filter, transform, apply
rng = np.random.RandomState(0)
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': range(6),
'data2': rng.randint(0, 10, 6)},
columns = ['key', 'data1', 'data2'])
# 聚合 aggregate
df.groupby('key').aggregate(['min', np.median, max])
# 在每一列指定统计函数
df.groupby('key').aggregate({'data1': 'min', 'data2': 'max'})
# 过虑 filter
def filter_func(x):
return x['data2'].std() > 4
df.groupby('key').filter(filter_func)
# 转换 transform
df.groupby('key').transform(lambda x: x - x.mean())
# 应用. apply
def norm_by_data2(x):
# x是一个分组数据的DataFrame
x['data1'] /= x['data2'].sum()
return x
df.groupby('key').apply(norm_by_data2)
设置 GroupBy 的 键
# 将列表、数组、Series 或索引作为分组键
L = [0, 1, 0, 1, 2, 0]
df.groupby(L).sum()
df.groupby(df['key']).sum()
# 用字典或 Series 将索引映射到分组名称
df2 = df.set_index('key')
mapping = {'A': 'vowel', 'B': 'consonant', 'C': 'consonant'}
df2.groupby(mapping).sum()
# 任意 Python 函数
df2.groupby(str.lower).mean()
# 多个有效键构成的列表
df2.groupby([str.lower, mapping]).mean()
数据透视表
Pivot table, 它将每一列数据作为输入, 输出将数据不断细分成多个维度统计信息的二维数据表. 更像是一种多维的 GroupBy 统计操作.
import numpy as np
import pandas as pd
import seaborn as sns
# wget -c https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv
# 普通使用
titanic = sns.load_dataset('titanic')
titanic.groupby('sex')[['survived']].mean()
titanic.groupby(['sex', 'class'])['survived'].aggregate('mean').unstack()
# 通过 pivot_table 方式
titanic.pivot_table('survived', index='sex', columns='class')
age = pd.cut(titanic['age'], [0, 18, 80])
titanic.pivot_table('survived', ['sex', age], 'class')
pivot_table 方法完整签名(0.18 Pandas 版本)
DataFrame.pivot_table(data, values=None, index=None, columns=None,
aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
处理字符串
如果只是简单地处理, 在数据出现缺失值, 会引起异常. 如
data = ['peter', 'Paul', None, 'MARY', 'gUIDO']
[s.capitalize() for s in data]
# 这时可用 Pandas 的 str 属性来处理
names = pd.Series(data)
names.str.capitalize()
Pandas 所有可处理的字符串方法都可 pandas对象.str.XXXX() , 如 names.str.lower()
处理时间序列
Pandas 最初是为金融模型而创建的
原生
from datetime import datetime
from dateutil import parser
datetime(year=2015, month=7, day=4)
date = parser.parse("4th of July, 2015")
date.strftime('%A')
格式化字符 https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior
NumPy 的 datetime64 类型
import numpy as np
date = np.array('2015-07-04', dtype=np.datetime64)
date + np.arange(12)
np.datetime64('2015-07-04')
# 设置单位
np.datetime64('2015-07-04 12:59:59.50', 'ns')
Pandas 的 Timestamp
import pandas as pd
date = pd.to_datetime("4th of July, 2015")
date
date.strftime('%A')
# 向量化计算
date + pd.to_timedelta(np.arange(12), 'D')
Pandas 时间序列
index = pd.DatetimeIndex(['2014-07-04', '2014-08-04', '2015-07-04', '2015-08-04'])
data = pd.Series([0, 1, 2, 3], index=index)
# 切片
data['2014-07-04':'2015-07-04']
- 时间戳:
Timestamp - 周期数据:
Period - 时间增量:
Timedelta
任何 DatetimeIndex 都可以通过 to_period() 转换成 PeriodIndex:
# to_datetime 的参数是时间序列, 则会返回一个 DatetimeIndex
dates = pd.to_datetime([datetime(2015, 7, 3), '4th of July, 2015', '2015-Jul-6', '07-07-2015', '20150708'])
dates.to_period('D')
TimedeltaIndex : 用一个日期减另一个日期时就会返回 TimedeltaIndex
dates - dates[0]
有规律的时间序列
pd.date_range()
pd.date_range('2015-07-03', '2015-07-10')
pd.date_range('2015-07-03', periods=8)
# 默认是 D
pd.date_range('2015-07-03', periods=8, freq='H')
pd.period_range('2015-07', periods=8, freq='M')
# 以时间递增的序列
pd.timedelta_range(0, periods=10, freq='H')
频率文档
https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#offset-aliases
获取股价
# conda install pandas-datareader
from pandas_datareader import data
goog = data.DataReader('GOOG', start='2004', end='2016', data_source='google')
goog.head()
重新取样与频率转换
from pandas_datareader import data
goog = data.DataReader('GOOG', start='2004', end='2016', data_source='google')
goog = goog['Close']
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn
seaborn.set()
goog.plot();
goog.plot(alpha=0.5, style='-')
# 重新取样
goog.resample('BA').mean().plot(style=':')
# 频率转换
goog.asfreq('BA').plot(style='--');
plt.legend(['input', 'resample', 'asfreq'],
loc='upper left');
移动均值
DataFrame.rolling(center=False,window=D).mean()
高性能运算
eval
import pandas as pd
nrows, ncols = 100000, 100
rng = np.random.RandomState(42)
df1, df2, df3, df4 = (pd.DataFrame(rng.rand(nrows, ncols)) for i in range(4))
# 获取局部变量, 可以用 @变量名
%timeit df1 + df2 + df3 + df4
%timeit pd.eval('df1 + df2 + df3 + df4')
支持的运算
- 算术运算
- 比较运算
- 位运算
- 对象属性与索引
query
# 获取局部变量, 可以用 @变量名
result2 = df.query('A < 0.5 and B < 0.5')
Matplotlib
import matplotlib as mpl
import matplotlib.pyplot as plt
显示
- 脚本环境 :
plt.show() - IPython 环境:
%matplotlib; import matplotlib.pyplot as plt. 强制刷新:plt.draw() - IPython Notebook 环境
%matplotlib notebook: Notebook 中启动交互式图形%matplotlib inline: Notebook 中启动静态图形
保存为文件
fig = plt.figure()
fig.savefig('my_figure.png')
# 导入图像文件
from IPython.display import Image
Image('my_figure.png')
# 查看支持的图片文件格式
fig.canvas.get_supported_filetypes()
两种画图接口
matlab 风格
位于 pyplot 接口中
plt.figure() # 创建图形
# 创建两个子图中的第一个,设置坐标轴
plt.subplot(2, 1, 1) # (行、列、子图编号)
plt.plot(x, np.sin(x))
# 创建两个子图中的第二个,设置坐标轴
plt.subplot(2, 1, 2)
plt.plot(x, np.cos(x))
这种接口最重要的特性是有状态的(stateful):它会持续跟踪“当前的”图形和坐标轴, 所有 plt 命令都可以应用.你可以用 plt.gcf() (获取当前图形)和 plt.gca()(获取当前 坐标轴)来查看具体信息.
面向对象接口
# 先创建图形网格
# ax是一个包含两个Axes对象的数组
fig, ax = plt.subplots(2)
# 在每个对象上调用plot()方法
ax[0].plot(x, np.sin(x))
ax[1].plot(x, np.cos(x))
线条的颜色与风格
# 颜色
plt.plot(x, np.sin(x - 0), color='blue')
plt.plot(x, np.sin(x - 1), color='g')
plt.plot(x, np.sin(x - 2), color='0.75')
plt.plot(x, np.sin(x - 3), color='#FFDD44')
plt.plot(x, np.sin(x - 4), color=(1.0,0.2,0.3))
plt.plot(x, np.sin(x - 5), color='chartreuse');
# 风格
plt.plot(x, x + 0, linestyle='solid')
plt.plot(x, x + 1, linestyle='dashed')
plt.plot(x, x + 2, linestyle='dashdot')
plt.plot(x, x + 3, linestyle='dotted')
# 风格缩写形式
plt.plot(x, x + 4, linestyle='-')
plt.plot(x, x + 5, linestyle='--')
plt.plot(x, x + 6, linestyle='-.')
plt.plot(x, x + 7, linestyle=':')
# 风格与颜色组合
plt.plot(x, x + 0, '-g')
plt.plot(x, x + 1, '--c')
坐标轴上下限
plt.xlim(10, 0)
plt.ylim(1.2, -1.2)
# 或
plt.axis([-1, 11, -1.5, 1.5]);
# 自动根据内容收紧坐标轴
plt.axis('tight')
设置图形标签
plt.title("A Sine Curve")
plt.xlabel("x")
plt.ylabel("sin(x)")
面向对象风格设置
ax = plt.axes() ax.plot(x, np.sin(x))
ax.set(xlim=(0, 10), ylim=(-2, 2), xlabel='x', ylabel='sin(x)',
title='A Simple Plot');
误差线
x = np.linspace(0, 10, 50)
dy = 0.8
y = np.sin(x) + dy * np.random.randn(50)
plt.errorbar(x, y, yerr=dy, fmt='.k')
图例
ax.legend(fancybox=True, framealpha=1, shadow=True, borderpad=1)
# 控制图例显示的元素. 默认会忽略不设置标签的元素
plt.plot(x, y[:, 0], label='first')
plt.plot(x, y[:, 1], label='second')
plt.plot(x, y[:, 2:])
plt.legend(framealpha=1, frameon=True)
机器学习
机器学习是从数据创建模型的学问
分类
- 有监督学习
- 分类 : 标签是离散值
- 回归 : 标签是连续值
- 无监督学习
- 聚类 : 将数据分成不同的组别
- 降维 : 用更简洁的方式表现数据
Scikit-Learn 数据表示
数据表
基本的数据表就是二维网格数据,其中的每一行表示数据集中的每个样本,而列表示构成 每个样本的相关特征
行: 称为样表. n_samples
列: 称为特征. n_features
特征矩阵
数据表通过二维数据或矩阵的形式将信息表达出来, 这类矩阵称为特征矩阵. 简记为变量 X . 它是维度为 [n_samples, n_features] 的二维矩阵.
目标数组
简记为y . 目标数组一般是一维数组, 其长度就是样本总数 n_samples . 通常用一维的 NumPy 或 Pandas 的 Series 表示.
Scikit-Learn 评估器API
使用步骤
- 从 Scikit-Learn 中导入适当的评估器, 选择模型类
- 用合适的数值对模型进行实例化, 配置模型超参数
- 整理数据, 获取特征矩阵和目标数组
- 调用模型实例的
fit()方法对数据进行拟合 - 对新数据应用模型.
- 对有监督学习模型中, 通常使用
predict()方法预测新数据的标签 - 对无监督学习模型中, 通常使用
transform()或predict()方法转换或推断数据的性质
- 对有监督学习模型中, 通常使用
有监督学习示例 : 线性回归
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x - 1 + rng.randn(50)
plt.scatter(x, y);
- 选择模型 :
from sklearn.linear_model import LinearRegression - 选择模型超参数. 有一些重要的参数, 必须在选择模型类时确定好. 这些参数通常称为
超参数, 即在模型拟合数据之前必须被确定的参数.model = LinearRegression(fit_intercept=True)(这只是存储了超参数的值, 还没将模型应用到数据上. Scikit-Learn 将选择模型和将模型应用到数据区别) - 将数据整理成特征矩阵和目标数组.
X = x[:, np.newaxis] - 用模型拟合数据:
model.fit(X, y) - 预测新数据的标签.
新数据是特征矩阵的 x 坐标值. 要用模型预测出目标数组的 y 轴坐标:xfit = np.linspace(-1, 11)- 将 x 转换成
[n_samples, n_feature]的特征矩阵形式, 输入到模型中:Xfit = xfit[:, np.newaxis] - 用模型预测:
yfit = model.predict(Xfit)
- 将 x 转换成
可视化结果
plt.scatter(x, y)
plt.plot(xfit, yfit);
完整代码
import matplotlib.pyplot as plt
import numpy as np
# 数据
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x - 1 + rng.randn(50)
plt.scatter(x, y)
# 选择模型
from sklearn.linear_model import LinearRegression
# 配置超参数
model = LinearRegression(fit_intercept=True)
# 整理特征矩阵
X = x[:, np.newaxis]
# 拟合数据
model.fit(X, y)
# 要预测数据
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
# 预测
yfit = model.predict(Xfit)
# 可视化
plt.scatter(x, y)
plt.plot(xfit, yfit)
有监督学习示例: 鸢尾花数据分类
高斯朴素贝叶斯 : 这个 方法假设每个特征中属于每一类的观测值都符合高斯分布
分割数据为训练集和测试集
import seaborn as sns
iris = sns.load_dataset('iris')
# 特征矩阵和目标数组抽取
X_iris = iris.drop('species', axis=1)
y_iris = iris['species']
# 分割训练集 train 和测试集 test
from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(X_iris, y_iris, random_state=1)
# 选择高斯朴素贝叶斯(Gaussian naive Bayes) 模型
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
# 拟合数据
model.fit(Xtrain, ytrain)
# 用测试集数据测试
y_model = model.predict(Xtest)
# 判断准确率
from sklearn.metrics import accuracy_score
accuracy_score(ytest, y_model)
无监督学习示例: 鸢尾花数据降维
主成分分析(principal component analysis,PCA) : 一种快速线性降维技术
from sklearn.decomposition import PCA
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis=1)
y_iris = iris['species']
# 配置超参数
model = PCA(n_components=2)
# 拟合数据
model.fit(X_iris)
# 将数据转换为二维
X_2D = model.transform(X_iris)
# 显示结果
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);
无监督学习示例: 鸢尾花数据聚类
聚类算法是要对没有任何标签的数据集进行分组.
高斯混合模型(Gaussian mixture model,GMM), GMM 模型试图将数据构造成若干服从高斯分布的概率密度 函数簇。
# 1.选择模型类
from sklearn.mixture import GaussianMixture
import seaborn as sns
from sklearn.decomposition import PCA
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis=1)
y_iris = iris['species']
model = PCA(n_components=2)
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
# 2.设置超参数,初始化模型
model = GaussianMixture(n_components=3,covariance_type='full')
# 3.拟合数据,注意不需要y变量
model.fit(X_iris)
# 4. 确定簇标签
y_gmm = model.predict(X_iris)
# 可视化
iris['cluster'] = y_gmm
sns.lmplot("PCA1", "PCA2", data=iris, hue='species',col='cluster', fit_reg=False);
超参考与模型验证
模型验证(model validation)
选择模型和超参数之后,通过对训练数据进行学习,对比模型对已知数据的预测值与实际值的差异.
正确方法: 即将数据分成训练习和测试集
from sklearn.model_selection import train_test_split
# 每个数据集分一半数据
X1, X2, y1, y2 = train_test_split(X, y, random_state=0, train_size=0.5)
# 用模型拟合训练数据
model.fit(X1, y1)
# 在测试集中评估模型准确率
y2_model = model.predict(X2)
accuracy_score(y2, y2_model)
更好的是: 交叉检验. 也就是做一组拟合,让数据的每个子集既是训练集,又 是验证集
y2_model = model.fit(X1, y1).predict(X2)
y1_model = model.fit(X2, y2).predict(X1)
accuracy_score(y1, y1_model), accuracy_score(y2, y2_model)
# 自动处理
from sklearn.cross_validation import cross_val_score
# 将数据分成 5 组, 每一轮依次用模型拟合其中的四组数据, 再预测第五组数据, 评估模型准确率
cross_val_score(model, X, y, cv=5)
偏差与方差的均衡
- 高偏差, 对数据欠拟合
- 高方差, 对数据过拟合
- $R^2$ : 判断系数, 用来衡量模型与目标值均值的对比结果
- 为 1, 表示模型与数据完全吻合
- 为 0, 表示模型不比简单取均值好
- 为负, 表示模型性能很差
验证曲线
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
def PolynomialRegression(degree=2, **kwargs):
return make_pipeline(PolynomialFeatures(degree), LinearRegression(**kwargs))
import numpy as np
def make_data(N, err=1.0, rseed=1): # 随机抽样数据
rng = np.random.RandomState(rseed)
X = rng.rand(N, 1) ** 2
y = 10 - 1. / (X.ravel() + 0.1)
if err > 0:
y += err * rng.randn(N)
return X, y
X, y = make_data(40)
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn; seaborn.set() # 设置图形样式
X_test = np.linspace(-0.1, 1.1, 500)[:, None]
plt.scatter(X.ravel(), y, color='black')
axis = plt.axis()
for degree in [1, 3, 5]:
y_test = PolynomialRegression(degree).fit(X, y).predict(X_test)
plt.plot(X_test.ravel(), y_test, label='degree={0}'.format(degree))
plt.xlim(-0.1, 1.0)
plt.ylim(-2, 12)
plt.legend(loc='best');
from sklearn.model_selection import validation_curve
degree = np.arange(0, 21)
train_score, val_score = validation_curve(PolynomialRegression(), X, y,
'polynomialfeatures__degree', degree, cv=7)
plt.plot(degree, np.median(train_score, 1), color='blue', label='training score')
plt.plot(degree, np.median(val_score, 1), color='red', label='validation score')
plt.legend(loc='best')
plt.ylim(0, 1)
plt.xlabel('degree')
plt.ylabel('score')
学习曲线
反映训练集规模的训练得分 / 验证得分曲 线被称为学习曲线(learning curve)
学习曲线最重要的特征是,随着训练样本数量的增加,分数会收敛到定值。因此,一旦你的数据多到使模型得分已经收敛,那么增加更多的训练样本也无济于事!
from sklearn.model_selection import learning_curve
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for i, degree in enumerate([2, 9]):
N, train_lc, val_lc = learning_curve(PolynomialRegression(degree), X, y, cv=7, train_sizes=np.linspace(0.3, 1, 25))
ax[i].plot(N, np.mean(train_lc, 1), color='blue', label='training score')
ax[i].plot(N, np.mean(val_lc, 1), color='red', label='validation score')
ax[i].hlines(np.mean([train_lc[-1], val_lc[-1]]), N[0], N[-1], color='gray',linestyle='dashed')
ax[i].set_ylim(0, 1)
ax[i].set_xlim(N[0], N[-1])
ax[i].set_xlabel('training size')
ax[i].set_ylabel('score')
ax[i].set_title('degree = {0}'.format(degree), size=14)
ax[i].legend(loc='best')
为模型和数据集画出学习曲线,可以帮你找到正确的方向,不断改进学习的效果
特征工程
向量化: 把任意格式的数据转换成具有良好特性的向量形式
分类特征
独热编码. 它可以有效增加额外的列,让 0 和 1 出现在 对应的列分别表示每个分类值有或无.
如果数据是像字典列表时, 可以用 SKLearn 的 DictVectorizer 实现
from sklearn.feature_extraction import DictVectorizer
# 适合当量字典型数据
vec = DictVectorizer(sparse=False, dtype=int)
# 如果有大量字典(枚举值), 那可以用稀疏矩阵
# vec = DictVectorizer(sparse=True, dtype=int)
data = [
{'price': 850000, 'rooms': 4, 'neighborhood': 'Queen Anne'},
{'price': 700000, 'rooms': 3, 'neighborhood': 'Fremont'},
{'price': 650000, 'rooms': 3, 'neighborhood': 'Wallingford'},
{'price': 600000, 'rooms': 2, 'neighborhood': 'Fremont'}
]
vec.fit_transform(data)
# 查看每一列的含义
vec.get_feature_names()
文本特征
单词统计 CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
sample = ['problem of evil',
'evil queen',
'horizon problem']
X = vec.fit_transform(sample)
X
import pandas as pd
pd.DataFrame(X.toarray(), columns=vec.get_feature_names())
原始的单词统计会让一些常用词聚集太高的权重,在分类算法中这样并不合理。解决这个问题的方法就是通过 TF–IDF(term frequency–inverse document frequency,词频逆文档频率),通过单词在文档中出现的频率来衡量其权重. IDF 的大小与一个词的常见程度成反比
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
sample = ['problem of evil',
'evil queen',
'horizon problem']
X = vec.fit_transform(sample)
pd.DataFrame(X.toarray(), columns=vec.get_feature_names())
图像特征
缺失值填充
对于一般的填充方法,如均值、 中位数、众数,Scikit-Learn 有 SimpleImputer 类可以实现:
from numpy import nan
X = np.array([[ nan, 0, 3], [ 3, 7, 9], [ 3, 5, 2], [4, nan, 6], [8, 8, 1] ])
y = np.array([14, 16, -1, 8, -5])
from sklearn.impute import SimpleImputer
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
X2 = imp.fit_transform(X)
X2
朴素贝叶斯分类
之所以称为“朴素”或“朴素贝叶斯”,是因为如果对每种标签的生成模型进行非常简单 的假设,就能找到每种类型生成模型的近似解,然后就可以使用贝叶斯分类.
贝叶斯主义(Bayesian formalism)的一个优质特性是它天生支持概率分类
$$ P(L | 特征) = \frac{P(特征|L) P(L)}{P(特征)} $$
高斯朴素贝叶斯
假设每个标签的数据都服从简单的高斯分布
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
# 数据训练数据, 可视化它
from sklearn.datasets import make_blobs
X, y = make_blobs(100, 2, centers=2, random_state=2, cluster_std=1.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='RdBu')
# 选择模型, 拟合
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X, y)
# 生成新数据来预测标签
rng = np.random.RandomState(0)
Xnew = [-6, -14] + [14, 18] * rng.rand(2000, 2)
ynew = model.predict(Xnew)
# 将这些新数据画出来,看看决策边界的位置
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='RdBu')
lim = plt.axis()
plt.scatter(Xnew[:, 0], Xnew[:, 1], c=ynew, s=20, cmap='RdBu', alpha=0.1)
plt.axis(lim)
# 后验概率
yprob = model.predict_proba(Xnew)
yprob[-8:].round(2)
多项式朴素贝叶斯
multinomial naive Bayes
多项式朴素贝叶斯非常 适合用于描述出现次数或者出现次数比例的特征。
# 下载测试数据
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups()
data.target_names
# 只测试以下四类
categories = ['talk.religion.misc', 'soc.religion.christian', 'sci.space',
'comp.graphics']
# 下载测试数据和训练数据
train = fetch_20newsgroups(subset='train', categories=categories) test = fetch_20newsgroups(subset='test', categories=categories)
# 创建模型
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
# 拟合
model.fit(train.data, train.target)
labels = model.predict(test.data)
# 用混淆矩阵统计测试真实标签与预测标签
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(test.target, labels)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=train.target_names, yticklabels=train.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');
# 生成了模型, 调用函数来测试输入数据
def predict_category(s, train=train, model=model):
pred = model.predict([s])
return train.target_names[pred[0]]
predict_category('sending a payload to the ISS')
线性回归
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
# 生成测试数据
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = 2 * x - 5 + rng.randn(50)
plt.scatter(x, y)
# 选择模型, 及拟合, 预测
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(x[:, np.newaxis], y)
xfit = np.linspace(0, 10, 1000)
yfit = model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit)
# 查看截距(intercept)和斜率(slope)
print("Model slope: ", model.coef_[0])
print("Model intercept:", model.intercept_)
# 多维度线性回归
rng = np.random.RandomState(1)
X = 10 * rng.rand(100, 3)
y = 0.5 + np.dot(X, [1.5, -2., 1.])
model.fit(X, y)
print(model.intercept_)
print(model.coef_)
支持向量机 SVM
有监督学习算法,既可 用于分类,也可用于回归
不再画一条细线来区分类 型,而是画一条到最近点边界、有宽度的线条.
支持向量机其实就是一个边界最大化评估器。
杂项
向量化处理新数据
# data 是向量化后的数据
data = vec.fit_transform(df.to_dict( orient = 'records' ))
# 处理新数据
newData = vec.transform(newClick.to_dict( orient = 'records' ))