<HikariCP 数据库连接池实践>笔记
 times read
times read
Contents
Linux 内核
文件句柄相关参数
# kernel 级别最大打开文件句柄数
sudo sysctl -w fs.file-max=3145728
sudo sysctl -w fs.nr_open=3145728
sudo sysctl -p
sudo echo 3145728 > /proc/sys/fs/nr_open
# 进程级别最大打开文件句柄数
ulimit -n 1048576
TCP 栈相关参数
# backlog
sudo sysctl -w net.core.somaxconn=32768
sudo sysctl -w net.core.netdev_max_backlog=16384
sudo sysctl -w net.ipv4.tcp_max_syn_backlog=16384
# buffer
sudo sysctl -w net.core.rmem_default=262144
sudo sysctl -w net.core.rmem_max=16777216
sudo sysctl -w net.core.wmem_default=262144
sudo sysctl -w net.core.wmem_max=16777216
sudo sysctl -w net.core.optmem_max=16777216
sudo sysctl -w net.ipv4.tcp_mem='16777216 16777216 16777216'
sudo sysctl -w net.ipv4.tcp_rmem='4096 65536 16777216'
sudo sysctl -w net.ipv4.tcp_wmem='4096 65536 16777216'
# time wait
sudo sysctl -w net.ipv4.tcp_max_tw_buckets=1048576
sudo sysctl -w net.ipv4.tcp_tw_recycle=0
sudo sysctl -w net.ipv4.tcp_tw_reuse=1
# timeout
sudo sysctl -w net.ipv4.tcp_fin_timeout=15
Socket 中的 linger 参数
如果 time wait 过多, 连接数过低, 通常建议在客户端设置.
高性能思路
- 同步转异步
- 请求合并
- 疏导 (拆分, 导流)
HikariCP
同步时钟
书中建议使用的是 chrony 这个来同步.
配置
# 必需配置.
# 注意, 对于 Spring Boot 项目, 需要使用的是 jdbcUrl 的方式配置. MySQL 的话也建议用 jdbcUrl 方式配置. 其他情况, 建议用 dataSourceClassName 配置
dataSourceClassName 或 jdbcUrl
username
password
初始化
HikariConfig hikariConfig = new HikariConfig();
HikariDataSource hikariDataSource = new HikariDataSource(hikariConfig);
常用配置
# 自动提交. 默认 true
autoCommit
# 从连接池中获取连接等待的最长时间. ms . 默认 30000, 即 30 秒. 最低为 250
connectionTimeout
# 在连接池中闲置的最大时间. 仅适用用 minimumIdle < maximumPoolSize 的情况下.
# 0 表示永不删除
# 最小值为 10000 (10 秒), 默认为 600000 (10 分钟)
idleTimeout
# 池中连接最大生命周期. 0 表示无限. 默认是 1800000 (30 分钟)
# 作者建议调整这个参数.设置为比 DB 连接时间限制短几秒钟.
# 书中作者推荐的是 mysql 的 time wait 值 - 5秒.
# 注意, mysql wait_timeout 的值单位是秒. 这里的单位是 ms
# https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html
maxLifetime
# 连接池给出连接之前进行查询, 以验证连接是否仍然正常. 如果驱动程序支持 JDBC4 , 则强烈不建议设置. 默认值: none
connectionTestQuery
# 连接池中最小空闲连接数. 若空闲连接数 < minimumIdle 并且总连接数 < maximumPoolSize , 则会努力添加其他连接. 但为了性能, 建议不要设置此值(这时与 maximumPoolSize 一样, 即固定大小) 默认值: 同 maximumPoolSize
minimumIdle
# 连接池中最大大小. 包括空闲和正使用的连接. 当达到时, 调用 getConnection() 调用将阻塞到上面设置的 connectionTimeout 毫秒的时间. 默认为 10.
maximumPoolSize
# 仅通过编程配置或 IoC 容器使用. 允许记录各种度量
metricRegistry
# 仅通过编程配置或 IoC 容器使用. 报告当前连接池健康状态信息
healthCheckRegistry
# 自定义连接池名字
poolName
非常用配置
# 如果连接池无法成功初始化连接时, 这个参数控制快速失败.
# > 0, 尝试获取初始连接的毫秒数. 这时应用会被阻塞. 如果超时也无法获取, 则抛出异常. 这个 timeout 是在 connectionTimeout 之后的.
# = 0, 则尝试获取并验证连接, 如果成功获取, 但验证失败, 则抛出异常, 连接池也不会启动. 如果无法获取连接, 连接池会启动, 但可能后面获取连接会失败.
# < 0 则绕过尝试, 在尝试获取连接时立即启动连接池.
# 默认 1 ms
initializationFailTimeout
# 是否在自己的事务中隔离内部池查询. 例如连接存活测试. 通常是只读的, 因此没必要. 仅在 autoCommit 禁用时才生效. 默认 false
isolateInternalQueries
# 是否可通过 JMX 挂起和恢复. 当被挂起时, getConnection() 将不会超时, 直到池恢复为止. 默认 false
allowPoolSuspension
# 获取的连接是否只读模式. 默认 false.
readOnly
# 是否注册 Mbean
registerMbeans
# 设置数据库默认的 catalog.
catalog
# 创建新连接后执行的 sql. 默认值无. 如果有值, 但执行 SQL 失败, 将视为连接失败.
connectionInitSql
# 旧的驱动器可能需要显式指定. 默认无.
driverClassName
# 连接池中连接的默认事务隔离级别. 它是 Connection 类的常量名. 如 TRANSACTION_READ_COMMITTED, TRANSACTION_REPEATABLE_READ
transactionIsolation
# connection 测试活性的最长时间. 该值必须小于 connectionTimeout . 最小为 250 . 默认为 5000 . 单位 ms
validationTimeout
# 控制一条 connection 被日志记为可能泄漏时间. 0 表示禁用检测. 最小为 2000 (2 秒). 默认为 0. 单位 ms
leakDetectionThreshold
# 仅可通过编程或 IoC 容器获得. 直接设置 dataSource , 而不是 HikariCP 反射来设置. 指定后, dataSourceClassName 属性以及所有 datasource 相关的属性都将被忽略. 默认 无
dataSource
# 默认 db 的 schema .
schema
# 仅可通过编程或 IoC 容器获得
threadFactory
# 仅可通过编程或 IoC 容器获得
scheduledExecutor
常用的 dataSourceClassName 如下 https://github.com/brettwooldridge/HikariCP#popular-datasource-class-names
| Database | Driver | DataSource class |
|---|---|---|
| Apache Derby | Derby | org.apache.derby.jdbc.ClientDataSource |
| Firebird | Jaybird | org.firebirdsql.ds.FBSimpleDataSource |
| H2 | H2 | org.h2.jdbcx.JdbcDataSource |
| HSQLDB | HSQLDB | org.hsqldb.jdbc.JDBCDataSource |
| IBM DB2 | IBM JCC | com.ibm.db2.jcc.DB2SimpleDataSource |
| IBM Informix | IBM Informix | com.informix.jdbcx.IfxDataSource |
| MS SQL Server | Microsoft | com.microsoft.sqlserver.jdbc.SQLServerDataSource |
| Connector/J | ||
| MariaDB | MariaDB | org.mariadb.jdbc.MariaDbDataSource |
| Oracle | Oracle | oracle.jdbc.pool.OracleDataSource |
| OrientDB | OrientDB | com.orientechnologies.orient.jdbc.OrientDataSource |
| PostgreSQL | pgjdbc-ng | com.impossibl.postgres.jdbc.PGDataSource |
| PostgreSQL | PostgreSQL | org.postgresql.ds.PGSimpleDataSource |
| SAP MaxDB | SAP | com.sap.dbtech.jdbc.DriverSapDB |
| SQLite | xerial | org.sqlite.SQLiteDataSource |
| SyBase | jConnect | com.sybase.jdbc4.jdbc.SybDataSource |
连接池大小
总体目标: 以最小的大小, 满足业务需求.
pool size = threads * ( task -1 ) + 1
不过具体还是要细测.
MySQL 高性能配置
prepStmtCacheSize
prepStmtCacheSqlLimit
cachePrepStmts
useServerPrepStmts
完整如下
jdbcUrl=jdbc:mysql://localhost:3306/simpsons
username=test
password=test
dataSource.cachePrepStmts=true
dataSource.prepStmtCacheSize=250
dataSource.prepStmtCacheSqlLimit=2048
dataSource.useServerPrepStmts=true
dataSource.useLocalSessionState=true
dataSource.rewriteBatchedStatements=true
dataSource.cacheResultSetMetadata=true
dataSource.cacheServerConfiguration=true
dataSource.elideSetAutoCommits=true
dataSource.maintainTimeStats=false
JDBC Logging
jdbcUrl=jdbc:mysql://localhost:3306/test
dataSource.logger=com.mysql.jdbc.log.StandardLogger
dataSource.logSlowQueries=true
dataSource.dumpQueriesOnException=true
JDBC 最佳实践
- 使用连接池
- 使用 PrearedStatement . 防 SQL 注入
- 禁用自动提交.
- JDBC 批处理
- 使用列名而不是索引来获取 ResultSet 数据
- 使用标准的 SQL 语句
- 使用缓存
- 正确使用数据库索引
关闭对象顺序
ResultSet -> Statement -> Connection
PreparedStatement 与 Statement
- Statement 会频繁编译 SQL. PreparedStatement 可对 SQL 预编译.
- Statement 多变量要用分隔符. 而 PreparedStatement 则使用占位符.
- PreparedStatement 可防 SQL 注入. 而 Statement 则有可能被 SQL 注入.
- 批处理时, Statement 可以发送不同的 SQL 语句. 而 PreparedStatement 只能针对同一种类型 SQL 语句.
JDBC 与 SPI
JDBC 4.0 之前, 开发人员需要基于 Class.forName("xxx") 的方式来装载驱动.
而 JDBC 4.0 可基于 SPI 机制来发现驱动提供商.通过在 META-INF/services/java.sql.Driver 文件里指定实现类的方式来暴露驱动提供者. 然后直接使用
Connection conn = DriverManager.getConnection(URL, USER, PWD);
//DriverManager.loadInitialDrivers 方法会自动加载有 SPI 文件提供实现的类, 然后调用 Class.forName("xxxx") 所以, 不用显式调用.
就可以获取连接了. 支持 JDBC 4.0 的驱动提供商, 一般都已经在自己的 jar 包中, 添加了上面的文件了的. 所以就不需要 Class.forName("xxx") 了. 比如 MySQL 的
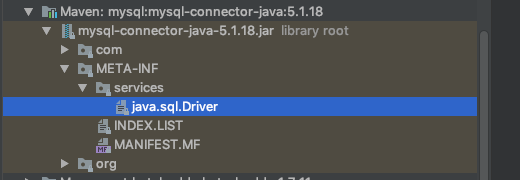
SPI 约定在
META-INF/services/目录下创建一个以服务接口命名的文件, 该文件里写的就是实现该服务接口的具体类. 当程序调用 ServiceLoader 的 load 方法时, 就能够通过约定的目录找到指定的文件, 并装载实例化, 完成服务的发现.
MySQL 线程池
Percona, MariaDB, 以及 Oracle MySQL 企业版有提供线程池.
# thread_handling . 如果是 one-thread-per-connection 则表示不启用. 如果值为 pool-of-threads 则表示启用
show variables like '%thread%'
Druid VS HikariCP
逸事
遇到的问题集锦
问题 : HikariPool-1 - Failed to validate connection com.mysql.cj.jdbc.ConnectionImpl@43541e8b (No operations allowed after connection closed.). Possibly consider using a shorter maxLifetime value
参考 https://github.com/brettwooldridge/HikariCP/issues/1326 . 通常是 MySQL 的 wait_timeout (show variables like '%wait_timeout%';) 比较小, 而连接池(HikariCP)默认比较大导致的. 参考上面的 maxLifetime 设置.
我项目实际的情况是: 使用了比较新版的 Spring Boot , 连接池是
com.mysql.cj.jdbc.Driver, 但实际的 MySQL Server 是 5.6 , 修改一下jdbc 库版本为就好了. (新版的话, 如果不指定 version , 则是8.0.17> <dependency> > <groupId>mysql</groupId> > <artifactId>mysql-connector-java</artifactId> > <version>5.1.18</version> > </dependency> > ``` > > # 设置事务 HikariCP 在手动管理连接时, 最后放回连接池会自动恢复到配置时的默认状态. 比如手动在 Connection 上设置了不同的事务级别, 在最后放回连接池时, HikariCP 会重置连接池的对象状态到初始状态.java try ( final Connection connection = sqlSessionFactory.openSession(ExecutorType.BATCH).getConnection(); final PreparedStatement pstmt = connection.prepareStatement(sql)) { //连接池会自动恢复为默认 connection.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED); for (WinPriceLog log : logs) { if (log == null) { continue; } pstmt.setString(1, log.getBidId()); pstmt.setString(2, log.getImpId()); pstmt.setString(3, log.getTaskId()); pstmt.setInt(4, log.getStrategyId()); pstmt.setInt(5, log.getBidPrice()); pstmt.setInt(6, log.getWaxPrice()); pstmt.setInt(7, log.getWinPrice()); pstmt.setTimestamp(8, new Timestamp(log.getUpdateTime().getTime())); pstmt.setTimestamp(9, new Timestamp(log.getBidTime().getTime())); pstmt.addBatch(); }
// Execute the batch
int[] updateCounts = pstmt.executeBatch();
return updateCounts.length;
}
```