前后端断点续传思路及简单实现
2019-05-17
 times read
times read
times read
Contents
前端
主要是利用 FileAPI 来进行按块大小分割, 然后一个一个上传.
主要就是利用 File 对象的 slice 方法进行按字节范围分割(一块), 然后一块一块地上传
还要完善的地方
script.js
(function () {
const uploadFile = document.getElementById('uploadFile');
if (uploadFile.files.length) {
upload();
}
uploadFile.addEventListener('change', upload, false);
function upload(e) {
const file = uploadFile.files[0];
const _1K = 1024;
const chunkSize = 1024 * _1K;
const chunks = Math.ceil(file.size / chunkSize);
const date = new Date();
const timestamp = date.getTime();
for (let i = 0; i < chunks; i++) {
(function (i) {
const isLast = (i == chunks - 1);
const start = i * chunkSize;
const end = isLast ? file.size : (i + 1) * chunkSize;
const chunk = file.slice(start, end, file.type);
const metaData = {
"fileName": file.name,
"fileSize": file.size,
"chunkSize": chunkSize,
"start": start,
"end": end,
"md5": timestamp,
"nth": i + 1,
"chunks": chunks,
};
send(metaData, chunk);
})(i);
}
}
function send(metaData, chunk) {
const oReq = new XMLHttpRequest();
let queryString = "";
for (let key in metaData) {
queryString += encodeURIComponent(key) + "=" + encodeURIComponent(metaData[key]) + "&";
}
oReq.open("POST", '/upload?' + queryString, true);
oReq.onload = function (oEvent) {
console.info(oEvent);
};
oReq.send(chunk);
}
})();
<!DOCTYPE HTML>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<title>分块上传</title>
</head>
<body>
<input type="file" id="uploadFile" />
<script src="script.js"></script>
</body>
</html>
后端(Java)
待完善的地方
[ ] 合并逻辑, 可以在后台异步执行, 完毕后再通知前端
@RequestMapping(value = "/upload", method = RequestMethod.POST) public String upload(HttpServletRequest request, int chunks, int nth, long start, long end, @RequestParam("fileName") String name, @RequestParam("fileSize") long totalLen, String md5) throws IOException { byte[] bodys = ByteStreams.toByteArray(request.getInputStream()); System.out.println("size > " + bodys.length); final String dirName = "/tmp/" + md5; File dir = new File(dirName); dir.mkdirs(); System.out.println(md5 + ", [" + start + " , " + end + "]" + " total " + totalLen); File file = new File(dirName + "/" + nth); //File dir = new File("/tmp/"); FileOutputStream fos = new FileOutputStream(file); fos.write(bodys); fos.flush(); fos.close(); return "ok"; }
主要就是读取 Request.getInputStream() 里(即前端上传的分块的原始数据). 然后根据 md5 创建一个目录, 然后在该目录下, 保持每块的数据文件.
待所有分块上传完后, 就可以合并了
@RequestMapping(value = "/merge", method = RequestMethod.POST)
public String upload(String name, String md5) throws IOException {
FileOutputStream dos = new FileOutputStream("/tmp/" + name);
//merge
File dir = new File("/tmp/" + md5);
File[] list = dir.listFiles();
Arrays.sort(list, Comparator.comparingInt(f -> Integer.parseInt(f.getName())));
System.out.println("order => " + list);
byte[] buf = new byte[1024];
for (File f : list) {
InputStream inputStream = new FileInputStream(f);
int len = 0;
while ((len = inputStream.read(buf)) != -1) {
dos.write(buf, 0, len);
}
inputStream.close();
}
dos.close();
for (File f : list) {
f.delete();
}
dir.delete();
return "ok";
}
RandomAccessFile
这个可以不用分块保存, 而是直接创建一个大小跟源文件一样的文件, 然后每次将它定位到相应的字节位置, 然后直接写入数据.
@RequestMapping(value = "/upload/raf", method = RequestMethod.POST)
public String uploadRaf(HttpServletRequest request, int chunks, int nth, long start, long end, @RequestParam("fileName") String name, @RequestParam("fileSize") long totalLen, String md5) throws IOException {
final RandomAccessFile randomAccessFile = new RandomAccessFile("/tmp/" + name, "rw");
randomAccessFile.setLength(totalLen);
byte[] bodys = ByteStreams.toByteArray(request.getInputStream());
randomAccessFile.seek(start);
randomAccessFile.write(bodys);
randomAccessFile.close();
return "ok";
}
测试截图
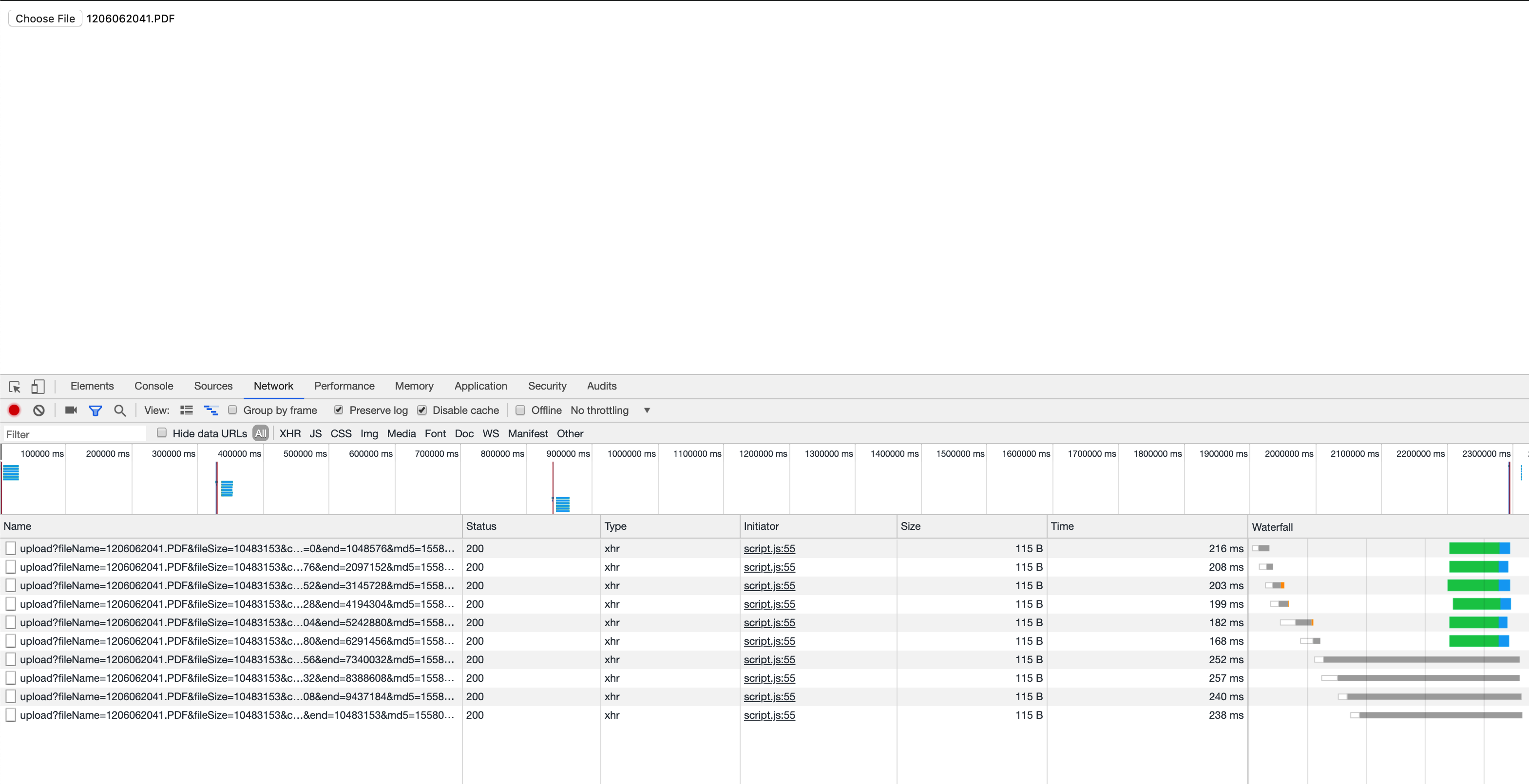

分块上传完后, 然后发送 curl -X POST --data-urlencode "name=1206062041.PDF" 'http://localhost:8080/merge?md5=1558065467506'
就可以看到在 /tmp/ 目录下就可以看到合并后的文件了
