<Apache Kafka实践>读书笔记
 times read
times read
Contents
Kafka 版本
kafka_2.11-1.0.0.tar.gz
2.11: 表示的是 Scala 语言版本1.0.0: 表示的是 Kafka 的版本
下载安装及使用
cd ~/Downloads
tar -xvf kafka_2.11-1.0.0.tgz
cd kafka_2.11-1.0.0
启动
要先安装好 Java 环境. 至少 JDK 1.7 及以上版本
zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
后台运行的话:
nohup bin/zookeeper-server-start.sh config/zookeeper.properties > zookeeper.log 2>&1 &
成功后可看到
binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
zookeeper 监听了 2181 端口
kafka
bin/kafka-server-start.sh config/server.properties
后台运行的话
bin/kafka-server-start.sh -daemon config/server.properties
或
nohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &
其实在脚本中 `-daemon` 参数效果等同于 `nohup xxx`
成功后可看到
INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
默认情况下 kafka 监听的是 9092 端口
关闭
bin/kafka-server-stop.sh
注意, 这会搜索当前机器中所有 Kafka broker 进程, 然后关闭它们.
简单使用测试
创建 topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic test --partitions 1 --replication-factor 1
Created topic "test".
查看 topic 状态
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
输入完后, 就可以不断输入消息了. 每一行一条消息. 最后按 `Ctrl-C` 退出
消费消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
....这里会输出上面产生的消息内容了....
Kafka 设计
高吞吐, 低延时设计目标
- 大量使用OS页缓存, 内存操作速度快且命中率高
- Kafka 不直接参与物理 I/O 操作, 而是交由最擅长此事的OS来完成
- 采用追加方式写入, 摒弃了缓慢的磁盘随机读/写操作
- 使用
sendfile为代表的zero-copy技术加强网络间的数据传输效率
消息持久化
所有的数据会立即被写入文件系统的持久化日志中, 之后 Kafka 服务器才会返回结果给客户端
负载均衡和故障转移
负载均衡
默认情况下 Kafka 每台服务都有均等机会为 Kafka 客户端提供服务
故障转移
通过会话机制. 在 Kafka 启动后以会话形式注册到 Zookeeper 上, 如果会话超时, Kafka 集群会选举出另一台服务器来完全代替这台服务器继续提供服务
伸缩性
通过 Zookeeper 保存轻量级状态来扩展 Kafka 集群
总结
- 生产者 => Kafka 服务器 ( Broker )
- Kafka 服务器 ( Broker ) => 消费者
- Kafka 服务器 ( Broker ) 依托 Zookeeper 集群进行服务协调管理
概念
消息
消息格式(图片来源于书)
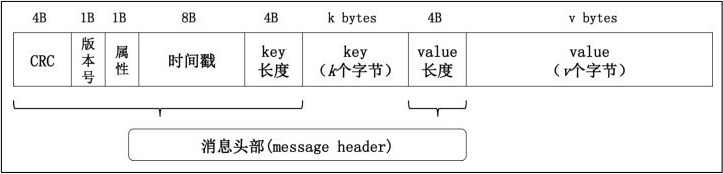
普通用度一般主要关注
- Key : 消息键
- Value : 消息体
- Timestamp: 消息发送时间戳. ( 于用流式处理及其依赖时间的处理说语义). 如果不指定则是当前时间
- 属性字段: 目前只使用最低的3 bit用于保存消息的压缩类型, 其余5 bit 尙未使用.
- 0: 无压缩
- 1: gzip
- 2: snappy
- 3: lz4
Kafka 避开繁重的 Java 堆中内存分配, 直接使用紧凑二进制字节数组 ByteBuffer 而不是独立的对象, 减少内存占用. 通常运行 Java 的OS默认都开启了页缓存机制, 也就是说堆上保存的对象很可能在页缓存中还保留了一份, 这造成极大的资源浪费.
页缓存还有一个好处: 当出现 Broker 进程崩溃时, 堆内存上的数据也一并消失, 但页缓存的数据依然存在. 下次 Broker 重启后可以继续提供服务, 不需要再单独”热”缓存了.
topic 和 partition
- topic
只是一个逻辑概念, 代表一类消息, 也可以认为是消息被发送的地方.
- partiton
它是 topic 的分区, 并没有太多的业务含义, 它的引入单纯就是为了提升系统的吞吐量.
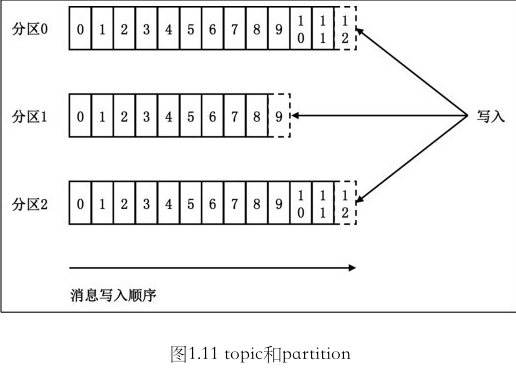
offset
- partition 中消息的 offset : 它是固定的.
- 消费者消费该partition 中的消息时, 它自己也有个 offset 会随着消费进度不断前移.
- 唯一定位消息
<topic, partition, offset>
replica
分布式系统实现高可靠性, 目前主要依靠冗余机制. 对 Kakfa 就是备份多份日志. 这备份日志在 Kafka 中被称为 replica (副本). 它的唯一 目的就是防止数据丢失 !
在创建主题时
--replication-factor N参数中的N = leader + follower, 如果N为1, 则只有 leader并且这个N, 不能大于当前可用的 broker 数量, 否则会报如下异常
Replication factor: 2 larger than available brokers: 1
leader replica
领导者副本. 对外提供服务
follower replica
追随者副本. 它是不能提供服务给客户端的. 它只是被动地向领导者副本 (leader replica) 获取数据, 而一旦 leader replica 所在的 broker 宕机, kafka 会从剩余的 replica 中选举出新的 leader 继续提供服务.
Kafka 保证, 同一个 partition 的多个 replica 一定不会分配在同一台 broker 中.
ISR 系统
in-sync-replica
即与 leader replica 保持同步的 replica 集合.这是 Kafka 动态维护一个 replica 的集合, 只有在这个集合中的 replica 才能被选举为 leader , 也只有在该集合中所有 replica 都接收到了同一条消息, Kafka 才会将该消息标识为 已提交 状态(即认为这条消息发送成功).
Kafka 承诺, 只要这集合中至少存在一个 replica, 那 已提交 的消息就不会丢失.
Kafka 适用场景
- 消息传输
- 网站行为日志追踪
- 审计数据收集
- 日志收集
- Event Souring
- 流式处理
Kafka 与 Confluent
confluent 分开源版本与企业版本. 开源版本跟 Kafka 并无太大区别
线上环境部署
OS
推荐 Linux. 新clients在底层时采用了 Java 的 Selector 机制, 它在 Linux 上的实现就是 Epoll. 但在 Windows 上, NIO 的 Selector 使用的是 Select 而非 IOCP (真正的异步I/O模型, 性能比较高). Java NIO2 才是使用 IOCP 实现的.因此, 用 Linux 部署 Kafka , I/O 上更高效
Zero-Copy 在 Linux 上支持良好. 如 sendfile, mmap 等
Java 8u60 版本Windows平台的, 才正式支持FileChannel.transferTo 调用类似Linux 的 sendfile 技术
磁盘
机械磁盘也够. 当然SSD更好
容量
- 新增消息数
- 消息留存时间
- 平均消息大小
- 副本数
- 是否启用压缩
内存
Kafka 只是将消息写入 page cache, 之后由OS刷到磁盘的.
consumer 读取时, 也会优先从该区域中查询, 如果直接命中则完全不用执行耗时的物理I/O操作
- 尽量分配更多的内存给OS的 page cache
- 不要为 broker 设置过大的堆内存, 最好不超过6GB
- page cache 大小至少要大于一个日志段的大小
CPU
追求多核而非高时钟频率.
使用 0.10.0.0 之前的版本或 clients 与 broker 端消息版本不一致, 则要防止消息解压操作消耗过多的CPU
带宽
- 尽量使用高速网络
- 避免使用跨机房网络
多节点环境安装
由一套多节点 Zookeeper 和一套多节点 Kafka 集群组成
zookeeper 集群
一个 zookeeper 集群通常称为一个 ensemble , 最好使用 奇数 个服务器, 即 2n+1, 这样 zookeeper 最多可容忍 n 台服务器宕机而保证依然提供服务.
zoo.cfg
tickTime=2000
dataDir=/usr/zookeeper/data_dir
clientPort=2181
initLimit=5
syncLimit=2
server.1=主机名或IP:2888:3888
server.2=主机名或IP:2888:3888
server.3=主机名或IP:2888:3888
tickTime: 小最时间单位, 用于丈量心跳时间和超时时间. 单位msdataDir: 保存内存快照的数据目录clientPort: 监听客户端的连接端口initLimit: follower 初始时连接 leader 的最大 tick 次数. 即syncLimit * tickTime内要连上 leader , 否则将被视为超时syncLimit: follower 与 leader 进步同步的最大时间. 类似initLimit, 以tickTime为单位来指定server.X=host:port1:port2: X必须是全局唯一的数字, 且需要与myid文件中的数字相对应.port1用于 follower 节点连接 leader 节点.port2用于 leader 选举
myid
这个要保存在 zoo.cfg 文件中的 dataDir 中, 内容就是上面指定server.X的一个数字X 即可.
多节点配置时配置文件的差别
clientPort这个如果在同一台机器上, 则需要不同的端口. 如果是不同的机器上, 则可以为相同端口(只要确保没有被占用即可)dataDir: 集群中的每个节点的数据目录也要不同.server.X=主机名或IP:2888:3888这些要修改为相应节点的不同的配置. 并确保这些端口没有被其他程序占用
启动集群
bin/zkServer.sh start conf/zoo1.cfg
bin/zkServer.sh start conf/zoo2.cfg
bin/zkServer.sh start conf/zoo3.cfg
查看集群状态
bin/zkServer.sh status conf/zoo1.cfg
bin/zkServer.sh status conf/zoo2.cfg
bin/zkServer.sh status conf/zoo3.cfg
Kafka 集群
创建多份配置. 每份配置的主要不同内容为(假设为 config/server1.properties, config/server2.properties, config/server3.properties )
broker.id: 0, 1, 2…等必须是全局唯一的listeners = listener_name://host_name:port: port 指定为不同的端口log.dirs日志数据文件目录. 最好修改为其他的而不是/tmpzookeeper.connect: 连接 zookeeper 集群. 要同时指定 zookeeper 集群中的所有 zookper 节点. 例如zookeeper.connect=127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002
启动
bin/kafka-server-start.sh -damon config/server1.properties
bin/kafka-server-start.sh -damon config/server2.properties
bin/kafka-server-start.sh -damon config/server3.properties
验证
创建主题
bin/kafka-topics.sh --zookeeper zk1:8001,zk2:8002,zk3:8003 --create --topic test-topic --partitions 3 --replication-factor 3
描述主题
bin/kafka-topics.sh --zookeeper zk1:8001,zk2:8002,zk3:8003 --describe --topic test-topic
删除主题
bin/kafka-topics.sh --zookeeper zk1:8001,zk2:8002,zk3:8003 --delete --topic test-topic
列出主题
bin/kafka-topics.sh --zookeeper zk1:8001,zk2:8002,zk3:8003 --list
发送消息
bin/kafka-console-producer.sh --broker-list kafka1:9092,kafka:9093,kafka:9094 --topic test-topic
然后输入内容, 最后 Ctrl-C 退出
消费消息
bin/kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka:9093,kafka:9094 --topic test-topic --from-beginning
生产者吞吐测试
bin/kafka-producer-perf-test.sh --topic test-topic --num-records 500000 --record-size 200 --throughput -1 --producer-props bootstrap.servers=kafka1:9092,kafka:9093,kafka:9094 acks=-1
消费者吞吐测试
bin/kafka-consumer-perf-test.sh --broker-list kafka1:9092,kafka:9093,kafka:9094 --fetch-size 2000 --messages 500000 --topic test-topic
参数设置
broker
config/server.properties
要生效的话, 要重启该 broker.
broker.id: 唯一的整数标识 broker. 如果不指定, kafka 会自动生成一个唯一值.log.dirs: 持久化消息的目录. 可以有多个目录, 以逗号分隔. 如/home/kafka1,/home/kafka2. 如果有N块磁盘, 则填写N个目录目录, 则可以极大提升同时写操作.zookeeper.connect: 连接 zookeeper 集群. 如果要管理多套kafka 集群, 则要指定 zookeeper 的chroot. 比如zk1:8181/kafka. 默认使用 zookeeper 的根路径.listeners: broker 监听器的CSV列表. 格式为协议://主机名:port,协议://主机名:port,协议://主机名:port. 该参数主要用于客户端连接 broker 使用, 可以认为是 broker 开放给 clients 的监听端口. 如果不指定主机, 则表示绑定默认网卡; 如果主机名为0.0.0.0则表示绑定所有网卡.advertised.listeners: 类似listeners, 但主要用于 IaaS 环境. 通常用来绑定公网IP提供外部 clients 使用. 然后上面的listeners绑定私网IP供 broker 间通信使用.unclean.leader.election.enable: 是否开启 unclean leader 选举. 默认为 false, 如果允许, 虽然 Kafka 继续提供服务, 但会造成消息数据的丢失. 对于可以容忍数据丢失的, 可以选为 true.delete.topic.enable: 是否允许 kafka 删除 topic.log.retention.{hours|minutes.ms}: 消息数据留存时间. 优先级为ms > minutes > hours. (新版本的Kafka会根据消息的时间戳来进行判断, 旧的版本没有时间戳格式, 则根据日志文件的最近修改时间来判断)log.retention.bytes: 控制每个消息日志保存多大的数据. 默认为-1, 即不根据大小来删除日志.min.insync.replicas: 与producer的acks配合使用.acks=-1, 表示最高级别的持久化保证.min.insync.replicas也只有acks=-1时才有意义. 指定 broker 成功响应 clients 消息发送的最少副本数. 假如无法满足的话, 消息会被认为发送不成功.min.insync.replicas=-1表示要将将消息写入所有副本中才算成功.num.network.threads: 控制 broker 在后台用于处理网络请求的线程数.(其实只是负责转发请求).num.io.threads: 实际处理网络请求的线程数.message.max.bytes: 能够接收的最大消息大小. 默认为977KB.
topic
delete.retention.ms: 每个 topic 可以设置自己的日志留存时间以覆盖全局默认值max.message.bytes: 覆盖全局的message.max.bytesretension.bytes: 覆盖全局的log.retension.bytes
GC
作者在书的给出的参数(JDK 8)
-Xmx6g -Xms6g -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80
OS
ulimit -n 100000- Socket 缓存区大小
- Ext4或XFS文件系统
- 关闭 Swap
sysctl vm.swappiness=一个较小的数值降低对 swap 空间的使用 - 设置更长的 flush 时间
/proc/sys/vm/dirty_writeback_centisecs单位为百分秒. 默认值为500, 即5秒./proc/sys/vm/dirty_expire_centisecs百分秒默认为3000, 即30秒
Producer 开发
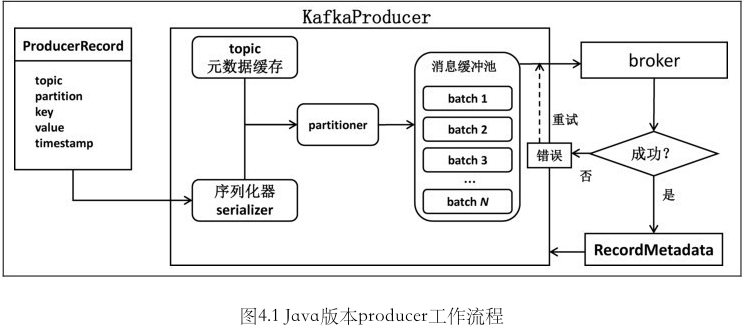
步骤
- 构造一个
java.util.Properties对象. 至少指定bootstrap.servers,key.serializer和value.serializer - 通过
Properties对象构造KafkaProducer对象 - 构造
ProducerRecord, 指定要发送到的topic,partition以及对应的key,value. (partition 和 value 可以不指定而由 Kafka 自行确定) - 调用
KafkaProducer.send方法 - 关闭
KafkaProducer
可重试异常
org.apache.kafka.common.errors.RetriableException 所有继承这个类的都是可重试异常, 否则一般是不可重试异常.

常见配置
配置文档 producer config
acks- 0 : 表示完全不理 leader broker 的处理结果, 然后可立即发送下一条消息 (通常这种情况下吞吐量是最高)
- all 或 -1 : 等待 leader broker 和所有 ISR 中所有副本都成功写入才将响应结果发送给 producer .(通常这种情况下, 吞吐量是最低的)
- 1 : 默认值. 仅 leader broker 成功写入就响应给 producer, 而无须等待 ISR 中其他副本是否成功写入.(吞吐介于 0 和 -1 之间)
直接在 properties 对象中增加
properties.put(ProducerConfig.ACKS_CONFIG, "1");即可. 注意, value是 String 类型
buffer.memory
缓存消息的缓冲区大小, 单位是字节. 默认为 33554432, 即 32MB.
producer => buffer.memory => io thread => broker
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
compression.type- lz4
- none
- gzip
- snappy
是否压缩, 默认为 none. 开启压缩会额外CPU消耗.
!!!!!
如果 producer 与 broker 的压缩设置不同, 则broker 会在写入消息之前对相应的消息进行解压 => 重压缩 操作.
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "lz4");
retries
表示重试次数.
注意可能导致消息重复发送. 这要求在 consumer 执行去重
消息乱序. (可通过
max.in.flight.requests.per.connection设置为1, 这会确保同一时刻只能发送一次请求)properties.put(ProducerConfig.RETRIES_CONFIG, 100);retry.backoff.ms
重试间隔停顿时间, 默认为 100ms
batch.size
非常重要的参数之一. producer 会将发送到同一分区的多条消息封装进一个 batch 中. 当 batch 满了或超过时间 linger.ms 时就会发送给 broker.
默认为 16384, 即 16KB.
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 1048576);
linger.ms
默认为0, 表示立即发送, 而无须关心 batch 是否被填满.
properties.put(ProducerConfig.LINGER_MS_CONFIG, 100);
request.timeout.ms
指定 broker 返回给 producer 的超时时间. 默认为 30 秒.
properties.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);
消息分区机制
默认分区机制
默认的分区器, 尽力确保具有相同的 key 的所有消息, 被发送到相同的分区上.
如果没有指定 key, 则选择轮询方式来确保消息在 topic 的所有分区中均匀分配. (但旧版的 producer 不是这样子实现)
默认情况下的分区器对有 key 的消息, 会根据 mermur2算法计算 hash, 然后对总分区数求模得到消息要被发送到的目标分区号.
自定义分区机制
- 创建一个类, 实现
org.apache.kafka.clients.producer.Partitioner接口. 在 Properties 中设置
partitioner.class参数.(完全限定类名)package hello; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; public class AppPartitioner implements Partitioner { @Override public int partition(final String topic, final Object key, final byte[] keyBytes, final Object value, final byte[] valueBytes, final Cluster cluster) { //分区策略的实现 return 0; } @Override public void close() { //释放资源 } @Override public void configure(final Map<String, ?> configs) { //初始化资源 } }
然后配置使用
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "hello.AppPartitioner");
序列化消息
默认
自定义
package hello;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.common.serialization.Serializer;
import java.util.Map;
public class AppSerializer implements Serializer {
private ObjectMapper objectMapper;
@Override
public void configure(final Map configs, final boolean isKey) {
objectMapper = new ObjectMapper();
}
@Override
public byte[] serialize(final String topic, final Object data) {
try {
return objectMapper.writeValueAsString(data).getBytes();
} catch (JsonProcessingException e) {
//log.error("erro", e);
return null;
}
}
@Override
public void close() {
objectMapper = null;
}
}
使用
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "hello.AppSerializer");
producer 拦截器
个人感觉类似 Web MVC 中的 interceptor.
实现 org.apache.kafka.clients.producer.ProducerInterceptor 接口
使用
final List<String> interceptorList = new ArrayList<>();
interceptorList.add("hello.AppInterceptor");
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptorList);
无消息丢失配置
block.on.buffer.full=true
0.9.0.0 版本标记为
deprecated, 并使用max.block.ms参数替代.
acks=all或-1retries=Integer.Max_VALUEmax.in.flight.reqeusts.per.connection=1使用带回调的
send方法callback 逻辑中, 显式地立即关闭 producer. 使用
close(0)
防乱序.
下面的是 broker 设置
unclean.leader.election.enable=falsereplication.factor=3min.insync.replicas=2replicatioin.factor > min.insync.replicasenable.auto.commit=false
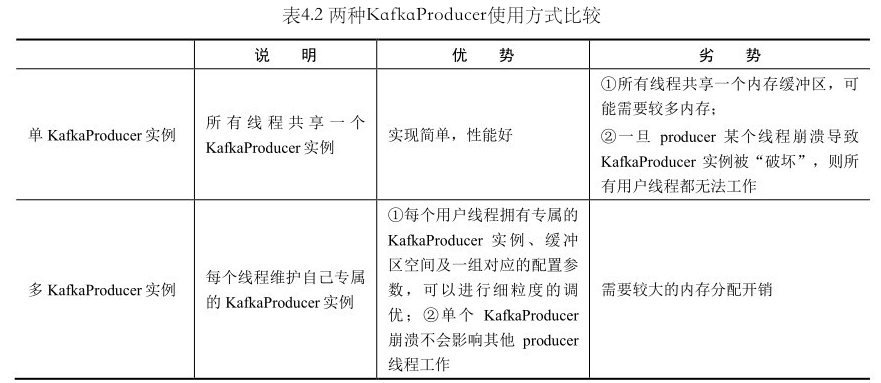
多线程使用 KafkaProducer 是线程安全的
KafkaProducer 是线程安全的.
- 多线程单实例 KafkaProducer
- 多线程多实例 KafkaProducer
旧版本 producer
也称为 Scala 版本 producer . 有很大的不同. 旧版本默认是同步发送, 新版本是异步发送.
不推荐使用旧版本了, 建议用新的 produder.
引入 kafka-core 依赖就可以使用旧版 producer
引入 kafka-clients 依赖就可以使用新版 producer
旧版本与 zookeeper 通信来发送数据
新版本直接与 kafka 集群来发送数据
Consumer 开发
consumer group
由多个消费者实例构成一个整体进行消费
消费者使用一个消费者组名(即 group.id ) 来标记自己, topic 的每条消息都只会被发送到每个订阅它的消费者组的一个消费者实例上.
Kafka 通过 consumer group 来实现 基于队列和基于发布/订阅的两种消息模型.
- 所有 consumer 都属于相同 group : 实现基于队列的模型. 每条消息只会被一个 consumer 实例处理
- consumer 实例都属于不同 group : 实现基于发布/订阅的模型. 极端情况下每个 consumer 设置完全不同的 group, 这样消息就会被广播到所有 consumer 实例上
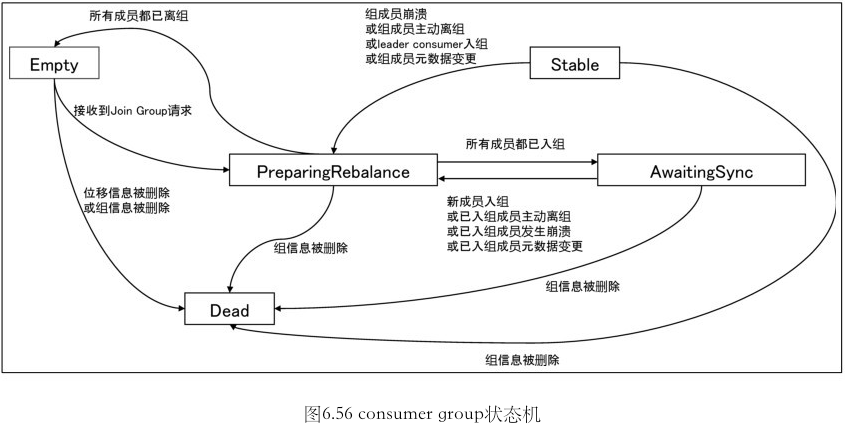
rebalance
这个概念只对 consumer group 有.
consumer group 中多个 consumer 可以同时读取 Kafka 消息, 一旦某个 consumer 挂了, consumer group 会立即将已崩溃的 consumer 负责的分区转交给其他 consumer 来负责. 这个过程称为 rebalance
这是个协议, 规定了一个 consumer group 下所有的 consumer 如何达成一致来分配订阅 topic 的所有分区.
触发条件
- 组成员发生变更
- 组订阅的 topic 数发生变更
- 组订阅的 topic 的分区数发生变更
分配策略
通过参数
partition.asignment.strategy来设置
- range : 范围. 也是默认策略
- round-robin : 轮询
- sticky : 考虑历史数据 (
0.11.0.0版本才引入) - 自定义分配器
总结
- consumer group 下可有一个或多个 consumer 实例
group.id唯一标识一个 consumer group- 对某个 group 而言, 订阅
topic 的每个分区只能分配给该 group 下的一个 consumer 实例(当然, 该分区还可以分配给其他订阅该 topic 的 consumer group). 注意, 是该 topic 的每个分区, 只会分配给同一个 group 下的一个 consumer.
standalone consumer
单独执行消费操作
offset
每个 consumer 实例都会为它消费的分区维护属于自己的位置信息来记录当前消费了多少条消息, 这就是consumer 的 offset
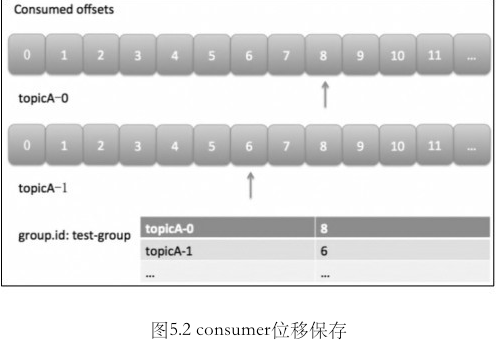
offset commit
consumer 需要定期向 Kafka 集群汇报自己消费数据的进度, 这一过程就是 offset commit
- 旧版本 consumer 依赖 zookeeper 来保存 offset (当然旧版本也提供了一个参数
offsets.storage=kafka来将 offset 提交到 kafka (__consumer__offsets这个 topic), 但默认是 zookeeper.) - 新版本 consumer 提交到 Kafka 内部的一个 topic (
__consumer__offstes) 上, 所以不用再依赖 zookeeper
__consumer__offsets
这个是内部的 topic, 则 kafka 自己创建, 用来保存 consumer 或 consumer group 的 offset commit. 千万不要随时删除个 topic 的数据.
构建 consumer
package hello;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class AppConsumer {
public static void main(String[] args) {
final String topic = "test-topic";
final String groupId = "test-group";
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.println("offset = " + record.offset());
System.out.println("key = " + record.key());
System.out.println("value = " + record.value());
}
}
} finally {
consumer.close();
}
}
}
- 构建 Properties 对象, 至少要指定
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIGConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIGConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIGConsumerConfig.GROUP_ID_CONFIG
- 通过 Properties 对象构造 KafkaConsumer
- 调用 KafkaConsumer.subscribe 订阅 consumer group 感兴趣的 topic
- 循环调用 KafkaConsumer.poll 来获取 topic 的消息
- 处理 ConsumerRecord 对象
- 关闭 KafkaConsumer
订阅主题
- 订阅一个
- 订阅多个
- 通过正则来匹配, 如
consumer.subscribe(Pattern.compile("log.app.*"));
注意 subscribe 方法并不是增量式的, 这意味着, 最后设置的订阅主题, 会覆盖前面的.
Consumer 主要参数
session.timeout.ms- consumer group 检测组内成员发送崩溃的时间.
- consumer 消息处理逻辑的最大时间 – 两次 poll 之间的间隔超过了该参数指定的阈值. 这时 coordinator 会认为这个 consumer 追不上组内其他成员消费进度, 这时会将该 consumer 踢出该 consumer group, 该 consumer 负责的分区会被分配给其他的 consumer 来处理. 被踢出的 consumer 会无法 offset commit, 导致 rebalance 后, 会重新消费一次消息.
- 在
0.10.1.0版本及以后版本, 则只有一种含义:coordinator检测失败的时间. 因此在这些版本中, 设置一个比较小的值来快速检测失败. 默认为 10 秒.
max.poll.interval.ms: 从上面session.timeout.ms中consumer 处理逻辑最大时间的含义剥离出来的.auto.offset.reset:无位移信息(如刚开始时)或位移越界时Kafka 的对应策略.earliest: 从最早开始(不一定是0, 比如最近一次最后提交的位置开始 )latest: 从最新处开始none: 抛出异常
enable.auto.commit: 是否自动提交 offset. (类似 RabbitMQ 的 autoAck)fetch.max.bytes: consumer 单次获取数据的最大字节数.max.poll.records: 单次 poll 调用返回的最大消息数. 默认 500 条heartbeat.interval.ms: 当 coordinator 决定开启新一轮 rebalance 时, 它会将这个决定以REBALANCE_IN_PROGRESS异常的形式塞进 consumer 心跳请求中, 这样子其他成员拿到 response 后才能知道它需要重新加入 group. 这个参数就是用来做这件事的. 它要小于session.timeout.msheartbeat.interval.ms < session.timeout.msconnections.max.idle.ms: 定期关闭空闲 socket 的时间. 默认为 9分钟.-1的话表示不关闭空闲连接
Java Consumer 不是线程安全的
- 要定期执行其他子任务: poll(小超时) + 运行标识布尔变量的方式
- 不需要定期执行: poll(
MAX_VALUE) + 捕获 WakeupException 方式
consumer offset
语义
- 最多一次 at most once : 消息可能丢失, 但不会被重复处理 (消费之前提交)
- 最少一次 at least once : 消息不会丢失, 但可能被处理多次 (消费之后提交)(producer 默认提供的就是这个语义)
- 精确一次 exactly once : 消息一定会被处理且只会被处理一次
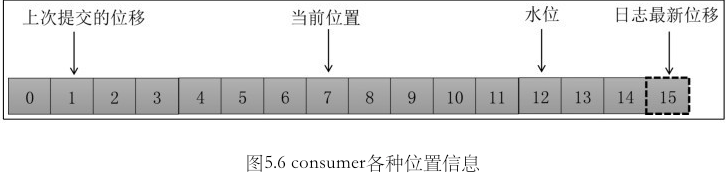
consumer 最多只能读取到 水位之前的消息, 而不是读取到水位之后的消息.
水位 : offset <= 水位, 被认为是”已提交”或”已备份”的意思.
自动与手动提交 offset
默认情况下是自动提交的, 间隔是 5 秒.
要想手动提交:
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
consumer.subscribe(Pattern.compile("log.app.*"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.println("offset = " + record.offset());
System.out.println("key = " + record.key());
System.out.println("value = " + record.value());
}
consumer.commitSync();
consumer.commitAsync();
}
} finally {
consumer.close();
}
- 关闭自动提交
- 调用
consumer.commitSync();或consumer.commitAsync();
更细粒度的提交
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println("value " + record.value());
}
final long offset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(offset + 1)));
}
}
} finally {
consumer.close();
}
注意, 提交的位移一定是consumer下一条待取消息的位置, 所以上面的代码使用了 offset+1
独立 consumer
package hello;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.errors.WakeupException;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class AppConsumer {
public static void main(String[] args) {
final String topic = "test-topic";
final String groupId = "test-group";
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
final List<TopicPartition> topicPartitions = new ArrayList<>();
final List<PartitionInfo> partitions = consumer.partitionsFor(topic);
for (PartitionInfo info : partitions) {
topicPartitions.add(new TopicPartition(info.topic(), info.partition()));
}
consumer.assign(topicPartitions);
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records) {
System.out.println("value " + record.value());
}
consumer.commitSync();
}
} catch (WakeupException e) {
//
} finally {
consumer.commitSync();
consumer.close();
}
}
}
assign 固定地为 consumer 指定要消费的分区.
Broker 端设计
消息格式
V0 版本
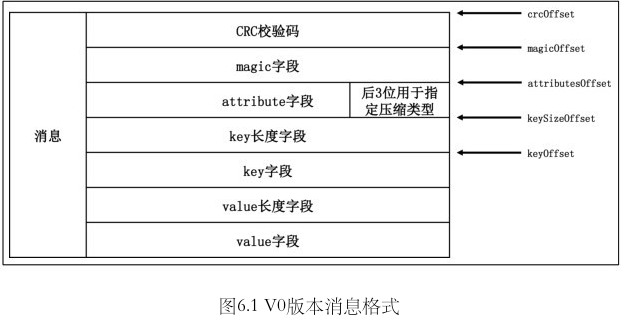
crc: 4 字节magic: 1 字节, 版本号. v0为0, v1为1, v2为2attribute: 1 字节key长度: 4字节. 未指定key时则为-1key值: key长度指定的大小. 如果 key 长度为-1, 则没有该字段value 长度: 4 字节. 若没有, 则为-1value 值: 消息value. 长度由上面指定. 如果长度值为-1, 则没有该字段.
除开 key 值 和 value 值之外, 统称为消息头部 (message header), 共 14 字节. 也就是说, V0版本的消息, 最小是14字节.(crc + magic + attribute + key长度 + value 长度 = 4 + 1 + 1 + 4 + 4 = 14 字节)
V1 版本
主要变化就是加入了时间戳字段.
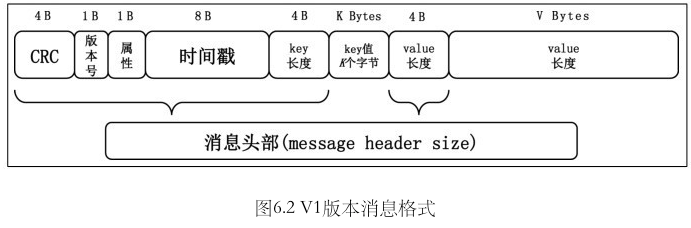
这个版本, 消息头部占22字节.
V1 VS v0 的区别
- 添加了时间戳
- attribute 字段中, 第4位用于指定时间戳的类型.
CREATE_TIME(表示由 producer 指定)LOG_APPEND_TIME(表示由 broker 指定)
v0, v1 日志项格式

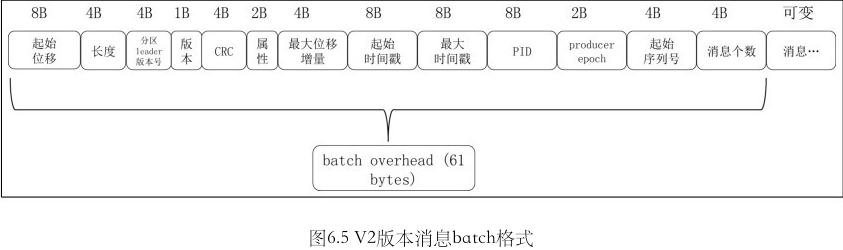
v2 版本

变化
- 增加消息总长度字段
- 保存时间戳增量
- 保存位移增量
- 增加消息头部. (v0, v1 是元数据, 对用户透明. v2这个 headers 是用户可见的.)
- 去除 crc 检验
- 废弃 attribute 字段. 统一放在 v2 版本中的 batch 格式字段
v2 batch 格式
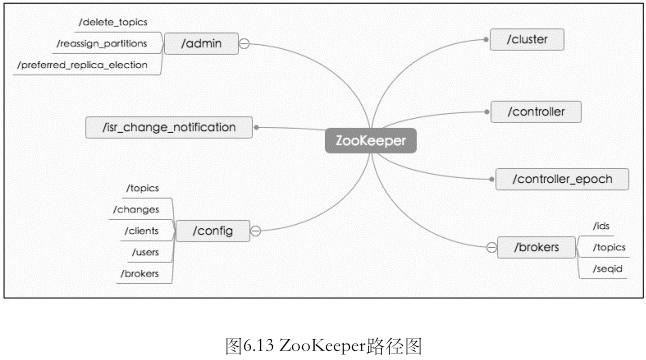
集群管理
通过 zookeeper . 每个 broker 启动时, 将自己注册到 zookeeper 下的一个节点. 路径为 chroot/brokers/ids/{broker.id}
历史各版本注册信息




zookeeper 路径
ISR 系统
0.9.0.0 版本以前
- 可通过
replica.lag.max.messages来控制 follower 落后于 leader 的最大消息数. 超过的话, 则该 follower 为不同步状态, 从而被踢出 ISR - 可通过
replica.lag.time.max.ms如果 follower 无法在该指定时间内向 leader 请求数据, 则该 follower 被视为不同步, 从而被踢出 ISR
0.9.0.0 版本之后
去掉了 replica.lag.max.messages , 只用 replica.lag.time.max.ms , 默认为10秒. (并且是持续性地超过这个时间才会被踢出 ISR)
底层文件系统
topic 在文件系统中创建了一个对应的子目录, 名字为 <topic>-<分区号>
xxxx.log 表示 xxx 位移 的信息.下一段的 yyyy.lo 表示 前一段共有 yyyy 条数据. 第一个log 文件为 00000000000000000000.log
xxxx.index 和 xxxx.timeindex 分别是位移索引和时间戳索引文件
controller
某个 broker 担任的角色. 管理集群中所有分区的状态并执行相应的管理操作.
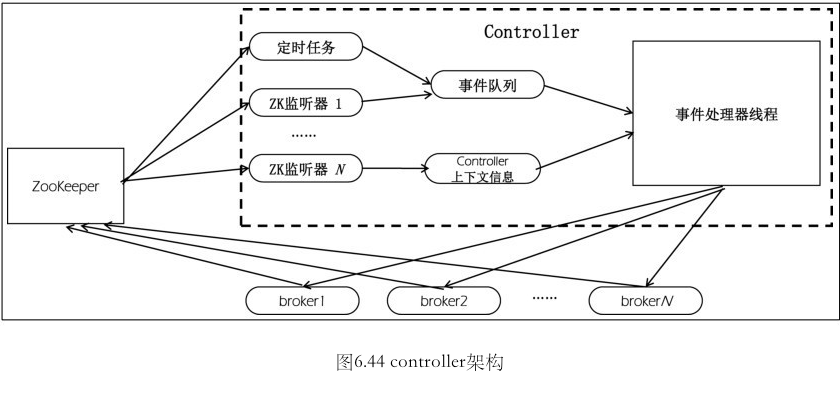
它的职责
- 更新集群元数据信息
- 创建 topic
- 删除 topic
- 分区重分配
- preferred leader 副本选举
- topic 分区扩展
- broker 加入集群
- broker 崩溃
- 受控关闭
- controller leader 选举
Producer 设计
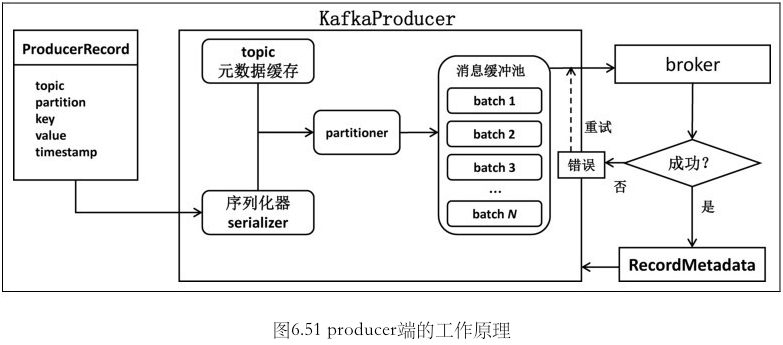
KafkaProducer 有一个专门的I/O线程负责将缓冲池中的消息分批次地发送给对应的 broker.
步骤
- 序列化 + 计算目标分区
- 追加写入消息缓冲区 (accumulator) . 大小由
buffer.memory参数指定) - Sender 线程预处理及消息发送
- Sender 线程处理 Response
Consumer group 状态机
事务
0.11.0.0 版本引入
幂等性 producer
若一个操作执行多次的结果与执行一次的结果是相同的, 那么该操作就是幂等操作.
对于单个 topic 分区而言, producer 这种幂等消除了各种错误导致的重复消息. 可在 producer 中设置参数 enable.idempotence 为 true . (这只能保证单个 producer 的 EOS 语义, 即精确一次且只有一次处理, 无法在多个 producer 中保证)
KafkaProducer producer = new KafkaProducer(properties);
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record0);
producer.send(record1);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
} finally {
producer.close();
}
JMX
export JMX_PORT=9997 bin/kafka-server-start.sh -daemon config/server.properties
查看消息元数据
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ../datalogs/kafka_1/00000000000000000.log --print-data-log
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ../datalogs/kafka_1/00000000000000000.log --deep-iteration
也可以看索引文件的元数据
性能收集
bin/kafka-producer-perf-test.sh --topic test --num-records 500000 --record-size 100 --throughput -1 --producer-props bootstrap.servers=localhost:9092 buffer.memory=104857600 acks=-1
杂项收集
从头开始消费
consumer.seekToBeginning(topicPartitions);
日志工作原理
在配置项 log.dir , 指定存储日志数据的路径. 每个主题都映射到指定日志路径下的一个子目录. 子目录数与主题对应的分区数目相同, 目录格式为 主题名_分区编号 . 每个目录存放用于追加传入的消息日志文件, 一旦日志文件达到某个规模, 或消息的时间戳达到所配置的时间间隔, 日志文件就会被切分.