<Druid实时大数据分析原理实践>读书笔记
 times read
times read
Contents
数据导入
定义数据源
数据格式
- 时间列(
timestamp)
每个数据集合都必须有时间列. 这个列是数据聚合的重要维度. 所有的查询都需要指定查询时间范围
- 维度列(
dimension)
用来标识一些事件 (event), 主要用于过滤或者切片数据. 通常为 字符串类型
- 指标列(
metric)
即用于聚合和计算的列. 通常为 数值类型. 如 Count, Sum, Mean 等
数据导入方式
- 实时 (
Kafka) - 批处理(
HDFS,CSV,JSON等)
数据查询
原生是使用 JSON 格式, 通过 HTTP 传送.
构架
- 分布式,
Lambda架构. - 实时数据处理: 面向
写多读少的优化 - 批处理部分是: 面向
读多写少的优化 - 采用
Shared nothing结构 - 使用
zookeeper协调 - 使用
MySQL提供元数据存储
自身节点组成
- 实时节点 (
realtime node) : 导入实时数据, 以及生成Segment数据文件 - 历史节点 (
historical node) : 加载已生成好的数据文件, 以供数据查询 - 查询节点 (
broker node) : 对外提供数据查询服务, 并同时从实时节点与历史节点查询数据, 合并后返回给调用方 - 协调节点 (
coordinator node) : 负责历史节点的数据负载均衡, 以及通过规则管理数据的生命周期
外部依赖
- 元数据库 (
Metastore) : 存储 Druid 集群的元数据信息. 比如Segment, 一般用MySQL或PostgreSQL - 分布式协调服务 (
Coordination) : 为Druid集群提供一致性协调服务的组件, 通常为Zookeeper - 数据文件存储库 (
deep storage) : 存放生成的Segment文件, 并供历史节点下载. 单节点集群可以是本地磁盘, 分布式集群一般是HDFS或NFS
Segement
结构
- 横向切割 : 通过参数
segmentGranularity, Druid 将不同时间范围内的数据存储在不同的 segment 数据块中 - 纵向切割 : 在 Segment 中也面向列进行数据压缩存储
制造与传播
- 实时节点生产出 Segment 数据文件, 并将其上传到 Deep Storage
- Segment 数据文件的元数据被存放在 MetaStore (即 MySQL 或 PostgreSQL )
- Master 节点 ( coordinator 节点) 从 metastore 里得知 Segment 数据文件的相关元信息后, 将其根据规则的设置分配给符合条件的历史节点
- 历史节点得到指令后会主动从 deep storage 中摘取指定的 segment 数据文件, 并通过 zookeeper 向集群声明负责提供该 segment 数据文件的查询服务
- 实时节点丢弃该 segment 数据文件, 并向集群声明其不再提供该 segment 数据文件的查询服务
扩展系统
下载扩展
java -classpath "/my/druid/lib/*" io.druid.cli.Main tools pull-deps --clean -c io.druid.extensions:mysql-metadata-storage:0.9.0
加载扩展
- 将扩展加载到 DruidService 的 classpath 中
- 或在
common.runtime.properties文件中通过druid.extensions.directory指定扩展目录
索引服务 Indexing Service
它同样也可以制造 Segment 数据文件.
主从结构
- 统治节点 (
Overlord Node) : 主节点 - 中间管理者 (
Middle Manager) : 从节点
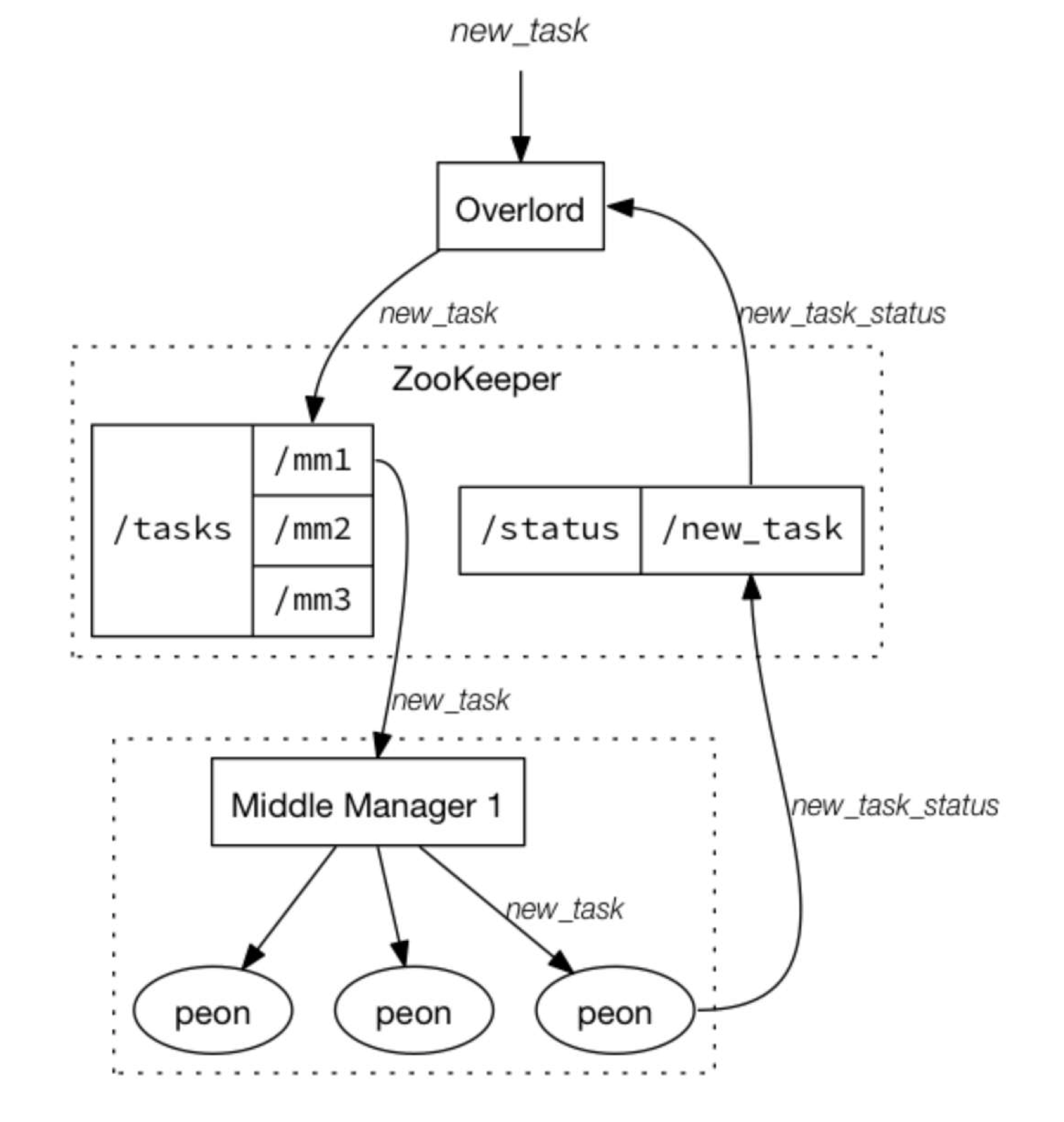
统治节点
本地模式 : 不仅负责集群的任务协调分配工作, 也负责启动一些苦工 (
peon) 来完成一部分具体任务远程模式 : 统治节点与中间管理者分别运行在不同的节点上, 仅负责协调分配工作, 不负责完成任务.
http://<overlord_ip>:<port>/druid/indexer/v1/task
http://<overlord_ip>:<port>/druid/indexer/v1/task/{taskId}/shutdown
http://<overlord_ip>:<port>/console.html
中间管理者与苦工
它是索引服务的工作节点, 负责接收统治节点分配的任务, 然后启动相关苦工即独立JVM来完成具体的任务
任务
| 父类 | type | 名称 | 描述 |
|---|---|---|---|
| 创建 segment | index_hadoop | hadoop 索引任务 | 利用 hadoop 集群执行 MapReduce 任务 以完成数据文件的创建, 适合体量比较大的数据文件的创建任务 |
| 创建 segment | index | 普通索引任务 | 利用 Druid 集群本身的系统资源来完成 segment 数据文件的创建, 适合体量较小的 segment 数据文件创建任务 |
| 合并 segment | append | 附加索引任务 | 将若干个 segment 数据文件首尾相连, 最终合成一个 segment 数据文件 |
| 合并 segment | merge | 合并索引任务 | 将若干个 segment 数据文件按照指定的聚合方法合并为一个 segment 数据文件 |
| 销毁 segment | kill | 销毁索引任务 | 彻底将指定的 segment 数据文件从 druid 集群包括 deep storage 上删除 |
| 混杂型 | hadoop_convert_segment | 版本转换任务 | 通常用来重定义 segment 数据文件的压缩方法等要素. 利用 hadoop 集群执行, 适合体量较大的 segment 数据文件的版本转换 |
| 混杂型 | convert_segment | 版本转换任务 | 利用 Druid 集群本身的系统资源完成 segment 数据文件的版本转换, 适合体量较小的 segment 数据文件的版本转换 |
| 混杂型 | noop | 无操作任务 | 将任务启动并沉睡一段时间, 并不完成具体的任何工作. 通常用来测试 |
服务启动与停止
以 imply 套件为例
nohup bin/supervise -c conf/supervise/quickstart.conf > quickstart.log &
bin/service --down
bin/service --restart {服务名}
| 服务 | 简介 | 访问地址 |
|---|---|---|
| zookeeper | ||
| coordinator | 协调节点, 管理集群状态 | http://localhost:8081 |
| broker | 查询节点, 处理查询请求 | http://localhost:8082/druid/v2 |
| historical | 历史节点, 管理历史数据 | http://localhost:8083/druid/v2 |
| overlord | 统治节点, 管理数据写入任务 | http://localhost:8090/console.html |
| middleManager | 中间管理者, 负责写数据处理 | |
| pivot | Web UI | http://localhost:9095 |
| tranquility-server | 实时写入服务, HTTP 协议 | http://localhost:8200/v1/post/datasource |
功能划分
- master : 管理节点. 包含
协调节点和统治节点. 负责管理数据写入任务及容错相关处理 - data : 数据节点, 包含
历史节点和中间管理者, 负责数据写入处理, 历史数据的加载与查询 - query : 查询节点, 包含
查询节点和pivot web 界面, 负责提供数据查询接口及web交互式查询功能
管理节点与查询节点配置
cp conf/supervise/master-no-zk.conf conf/supervise/master-with-query.conf
vim conf/supervise/master-with-query.conf
:verify bin/verify-java
:verify bin/verify-version-check
broker bin/run-druid broker conf
historical bin/run-druid historical conf
imply-ui bin/run-imply-ui conf
coordinator bin/run-druid coordinator conf
!p80 overlord bin/run-druid overlord conf
!pN 表示服务关闭顺序的权重. 默认50, 越大表示越先被关闭
运行
nohup bin/supervise -c conf/supervise/master-with-query.conf > master-with-query.log 2>&1 &
数据节点配置
vim conf/supervise/data.conf
:verify bin/verify-java
:verify bin/verify-version-check
historical bin/run-druid historical conf
middleManager bin/run-druid middleManager conf
运行
nohup bin/supervise -c conf/supervise/data.conf > data.log 2>&1 &
基础依赖配置
配置文件为 conf/druid/_common/common.runtime.properties
这里使用的是 imply-2.8.1 的示例代码. 具体请参考具体的版本. 书的版本比较旧
zookeeper
druid.zk.service.host=${zookeeper集群地址}
druid.zk.paths.base=/druid
MetadataStorage
书的版本比较旧, 指定了扩展配置
druid.extensions.loadList=[“mysql-metadata-storage”] , 新的好像已经默认加载了 mysql, postgresql 的 metadata-storage 扩展了, 所以就不用显式写了?
# For MySQL:
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://db.example.com:3306/druid
druid.metadata.storage.connector.user=...
druid.metadata.storage.connector.password=...
# For PostgreSQL:
druid.metadata.storage.type=postgresql
druid.metadata.storage.connector.connectURI=jdbc:postgresql://db.example.com:5432/druid
druid.metadata.storage.connector.user=...
druid.metadata.storage.connector.password=...
Deep Storage
# For local disk (only viable in a cluster if this is a network mount):
druid.storage.type=local
druid.storage.storageDirectory=var/druid/segments
# For HDFS:
#druid.storage.type=hdfs
#druid.storage.storageDirectory=/druid/segments
# For S3:
#druid.storage.type=s3
#druid.storage.bucket=your-bucket
#druid.storage.baseKey=druid/segments
#druid.s3.accessKey=...
#druid.s3.secretKey=...
配置调优
数据节点
- historical
middleManager
historical/ ├── jvm.config ├── main.config └── runtime.properties middleManager/ ├── jvm.config ├── main.config └── runtime.properties
查询节点
broker
broker/ ├── jvm.config ├── main.config └── runtime.properties
实际例子
将所有 JVM 参数(
find . -name "jvm.config")的-Duser.timezone=UTC设置为-Duser.timezone=UTC+0800
全局配置
配置 metadata storage, zookeeper, extennsions 等
conf/druid/_common/common.runtime.properties
全局日志文件配置
conf/druid/_common/log4j2.xml
Master
- coordinator : 协调节点
- overlord : 统治节点
- broker : 查询节点
- historical : 历史节点
Data
负责处理数据
- historical : 历史节点
- middleManager: 中间管理者
数据导入
流式数据源
- PUSH : 使用 Indexing Service 提供 HTTP 服务, 数据源通过调用这个 HTTP 服务推送到 Druid 系统
- PULL : 通过 Firehose 导入不同的流式数据. KafkaFirehose, RabbitMQFirehose 等
静态数据源
如文件系统中的文件等
可通过实时节点导入, 也可通过 Indexing Service 启动任务来导入
| 流式数据 | 静态数据 |
|---|---|
| PUSH(index task, hadoop index task) | PUSH(index task, hadoop index task) |
| PULL(Kafka Firehose, LocalFirehose) | PULL(Kafka Firehose, LocalFirehose) |
PULL
这个要定义一种称为 Ingestion Spec 文件来拉取. 它由三部分组成
{
"dataSchema" : {...}, # JSON 对象, 指明数据源格式, 数据解析, 维度等信息
"ioConfig" : {...}, # JSON 对象, 指明数据如何在 Druid 中存储
"tuningConfig": {} # JSON 对象, 指明存储优化配置
}
data schema
{
"datasource": "数据源名字",
"parser": {},
"metricsSpec": [] ,
"granularitySpec": {}
}
parser
JSON parser
{ "parser": { "type": "...", "parseSpec": { "format": "json", "timestampSpec": { "column": "时间戳列名", "format": "iso|millis|posix|auto|joda, 默认为 auto" }, "dimensionsSpec": { "dimensions": ["维度名1", "维度名2等等"], "dimensionExclusions": ["剔除的维度名列表, 可选"], "spatialDimentions": ["空间维度名列表, 地理几何运算, 可选"] }, "flattenSpec": { // json 对象 } } } }CSV parser
{ "parser": { "type": "...", "parseSpec": { "format": "csv", "columns": ["CSV数据列名"], "listDelimiter": "多值维度列, 数据分隔符, 可选", "timestampSpec": { "column": "时间戳列名", "format": "iso|millis|posix|auto|joda, 默认为 auto" }, "dimensionsSpec": { "dimensions": ["维度名1", "维度名2等等"], "dimensionExclusions": ["剔除的维度名列表, 可选"], "spatialDimentions": ["空间维度名列表, 地理几何运算, 可选"] }, "flattenSpec": { // json 对象 } } } }TSV parser
{ "parser": { "type": "...", "parseSpec": { "format": "tsv", "columns": ["TSV数据列名"], "listDelimiter": "多值维度列, 数据分隔符, 可选", "delimiter": "数据分隔符, 默认为 \t, 可选", "timestampSpec": { "column": "时间戳列名", "format": "iso|millis|posix|auto|joda, 默认为 auto" }, "dimensionsSpec": { "dimensions": ["维度名1", "维度名2等等"], "dimensionExclusions": ["剔除的维度名列表, 可选"], "spatialDimentions": ["空间维度名列表, 地理几何运算, 可选"] }, "flattenSpec": { // json 对象 } } } }
spatialDimentions
空间维度
{
"spatialDimentions": [
"dimName": "空间维度的名字. 如果一个空间维度已存在, 它必须是坐标值的数组. 必须",
"dims": ["lat", "long, 即包含空间维度的名字列表. 可选"]
]
}
metricsSpect
指明所有的指标列和所使用的聚合函数
{
"metricsSpec": [
{
"type": "count|longSum等聚合函数类型",
"fieldName": "聚合函数运用的列名, 可选",
"name": "聚合后指标列名"
}
]
}
granularitySpec
指定 segment 存储粒度和查询粒度
{
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "存储粒度, HOUR, DAY 等",
"queryGranularity": "最小查询粒度, MINUTE, HOUR 等",
"intervals": ["导入数据的时间段, 可以有多个值. 可选, 对于流式 PULL 可忽略"]
}
}
ioConfig
{
"ioConfig": {
"type": "realtime",
"firehose": {},
"plumber": "realtime"
}
}
不同的 firehose 的格式不太一样
tuningConfig
{
"tuningConfig": {
"type": "realtime",
"maxRowsInMemory": "在存盘之前中最大的存储行数, 指的是聚合后的行数",
"windowPeriod": "最大容忍时间窗口, 超过则数据丢弃",
"intermediatePersistPeriod": "多长时间刷盘一次",
"basePersistDirectory": "临时存盘目录",
"versioningPolicy": "如何为 segment 设置版本号",
"rejectionPolicy": "数据丢弃策略",
"maxPendingPersists": "最大同时存盘请求数, 达到上限, 将会暂停导入数据",
"shardSpec": {
//分片设置
},
"buildV9Directly": "是否直接构建 v9 版本索引",
"persistThreadPriority": "存盘线程优先级",
"mergeThreadPriority": "存盘合并线程优先级",
"reportParseExceptions": "是否汇报数据解析错误"
}
}
shardSpec
目前有两种分片方式, linear, numbered
{
"shardSpec": {
"type": "linear",
"partitionNum": 0
}
}
{
"shardSpec": {
"type": "numbered",
"partitionNum":0,
"partitions": 2
}
}
PUSH
需要索引服务. 所以要启动 MiddleManager (中间管理者), Overlord Node (统治节点).
将 Ingestion Spec 定义文件, 假设名为 index-task.json 发送一个 HTTP 请求
curl -X POST -H 'Content-Type:application/json' -d @index-task.json http://<overlord_ip>:<port>/druid/indexer/v1/task
索引服务任务相关接口
提交任务
curl -X POST -H 'Content-Type:application/json' -d @index-task.json http://<overlord_ip>:<port>/druid/indexer/v1/task查看任务状态
curl http://<overlord_ip>:<port>/druid/indexer/v1/task/{taskId}/status查看 segment 信息
http://<overlord_ip>:<port>/druid/indexer/v1/task/{segment_name之类}/segments关闭任务
curl -X POST http://<overlord_ip>:<port>/druid/indexer/v1/task/{taskId}/shutdownoverlord 控制台
http://<overlord_ip>:<port>/console.html
查询组件
- filter, 类似 SQL 中的 where
- selector filter
- regex filter
- logical expression filter
- search filter
- in filter
- bound filter.
>=,<=,=. 如果需要<,>, 则要指定lowerStrict或upperStrict的 值true - javascript filter : 通过写 JS 来代来自行判断 true 或 false, 参数为维度的值.
- aggregator
- count aggregator
- sum
- min/max
- cardinality
- hyperUnique
- javascript
- post-aggregator
- arithmetic
- field accessor
- constant
- hyperUnique cardinality
- query
- contains
- insensitive_contains
- fragment
- interval ,
>= && <=- 指定时间区间. 如
"intervals":["2016-08-28T00:00:00+08:00/2016-08-29T00:00:00+08:00"]
- 指定时间区间. 如
- context
Druid 监控
druid.emitter 来设置发送开关
- noop: 默认值. 不发送任何 metric 信息
- logging: 往日志写 metric 信息
- http: 通过 http 往外发送 metric 信息
性能相关收集
建议
- broker : 20G-30G 堆内存
- historical :
250MB * (processing.numThreads)堆内存 - coordinator : 默认即可?
Druid 大概 使用多少直接内存
估算公式
druid.processing.buffer.sizeBytes * (druid.processing.numMergeBuffers + druid.processing.numThreads + 1)