Socket参数资料收集与整理
 times read
times read
Contents
最近在看 <Unix 网络编程> 这本书, 发现好多关于网络编程的细节参数, 所以这里做个整理和总结.
socket 状态转换图
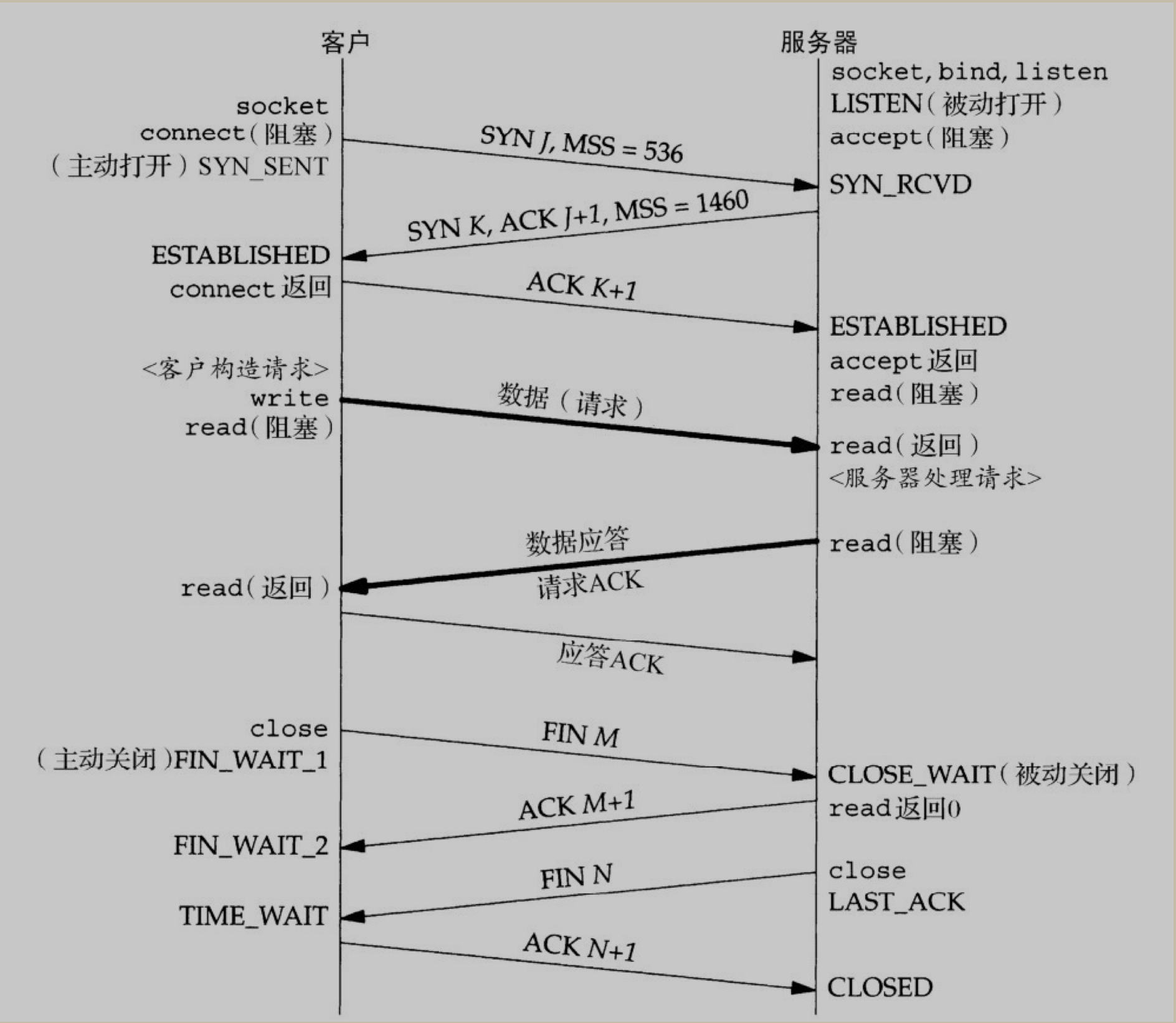
TCP 标志位解释
Flags (9 bits) (aka Control bits) . Contains 9 1-bit flags
- NS (1 bit): ECN-nonce - concealment protection (experimental: see RFC 3540).
- CWR (1 bit): Congestion Window Reduced (CWR) flag is set by the sending host to indicate that it received a TCP segment with the ECE flag set and had responded in congestion control mechanism (added to header by RFC 3168).
- ECE (1 bit): ECN-Echo has a dual role, depending on the value of the SYN flag. It indicates:
- If the SYN flag is set (1), that the TCP peer is ECN capable.
- If the SYN flag is clear (0), that a packet with Congestion Experienced flag set (ECN=11) in the IP header was received during normal transmission (added to header by RFC 3168). This serves as an indication of network congestion (or impending congestion) to the TCP sender.
- URG (1 bit): indicates that the Urgent pointer field is significant
- ACK (1 bit): indicates that the Acknowledgment field is significant. All packets after the initial SYN packet sent by the client should have this flag set.
- PSH (1 bit): Push function. Asks to push the buffered data to the receiving application.
- RST (1 bit): Reset the connection
- SYN (1 bit): Synchronize sequence numbers. Only the first packet sent from each end should have this flag set. Some other flags and fields change meaning based on this flag, and some are only valid when it is set, and others when it is clear.
- FIN (1 bit): Last packet from sender.
SO_BACKLOG
书中对这个参数的描述是这样子的:
内核为任何一个给定的监听套接字维护两个队列: 1. 未完成连接队列(incomplement connection queue), 每个这样的 SYN 分节对应其中一项: 已由某个客户发出并到达服务器, 而服务器正在等待完成相应的TCP三次握手过程. 这些套接字处于
SYN_RCVD状态 2. 已完成连接队列(completed connection queue), 每个已完成 TCP 三次握手过程的客户对应其中一项. 这些套接字处于ESTABLISHED状态
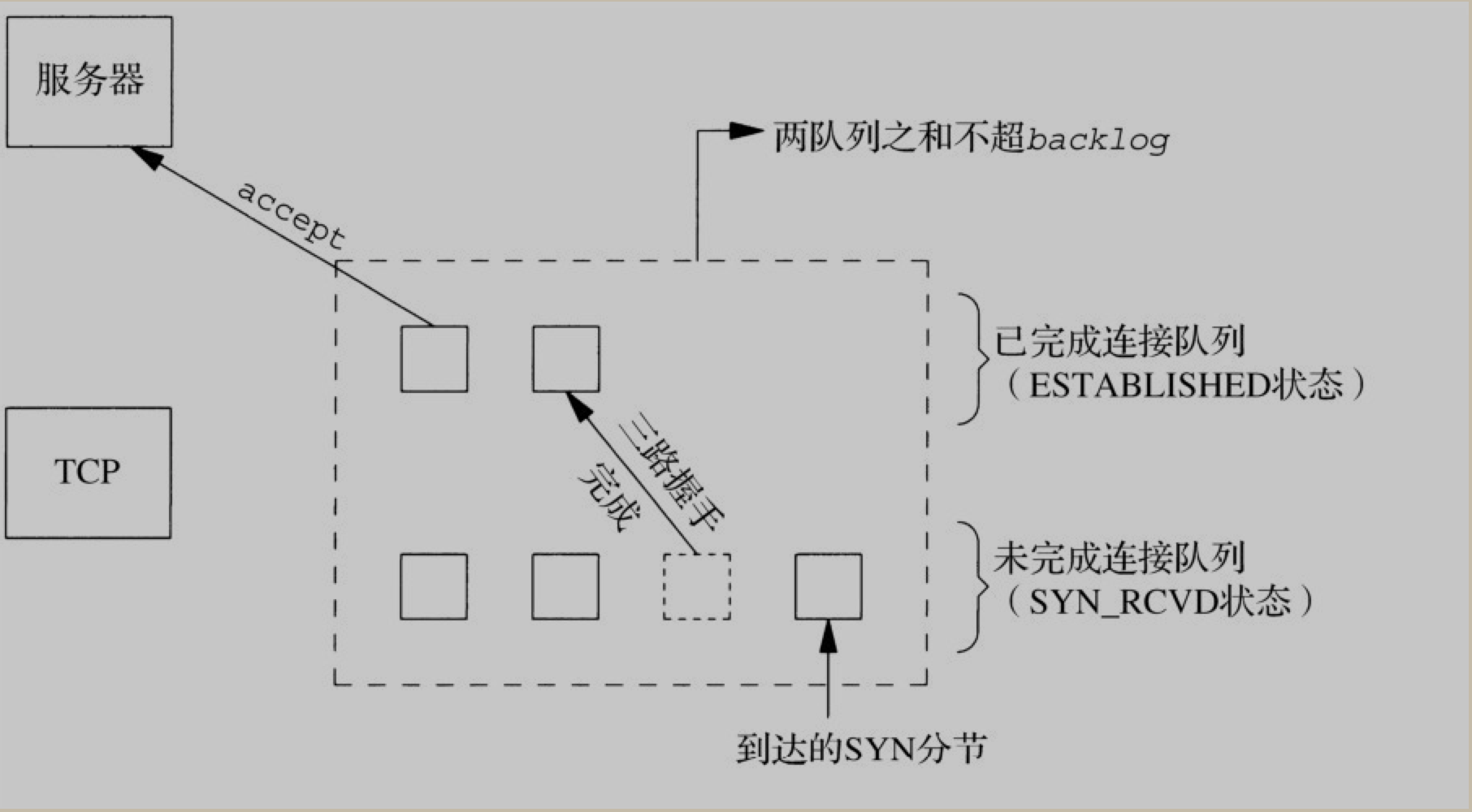
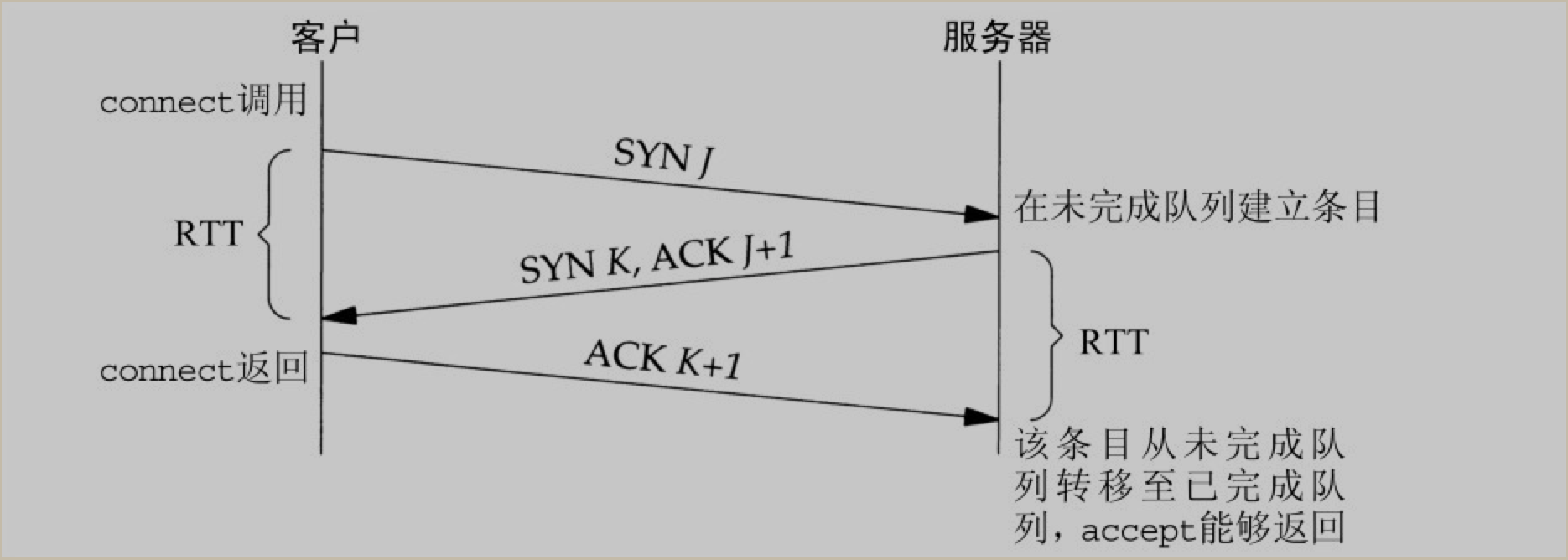
根据书中描述, 这个参数比较模糊. 曾被定义为是上面两个队列之和的最大值. 源自 Berkeley 的实现, 给 backlog 增加了一个模糊因子: 1.5 * backlog.
不过, 不要把 backlog 设置为0, 如果你不想监听套接字, 那就关掉它.
4.2BSD 版本支持的最大值为 5. 但当今许多系统允许修改该值.
更多详细内容, 可以参考 <Unix 网络编程> 第四章 4.5 小节
BSD 与 Linux 中的区别
这里只是对 How TCP backlog works in Linux 这篇文章的一些摘要及简要翻译
- BSD 中的实现, 虽然也是区分这两个队列了(SYN 与 ESTABLISHED), 但 backlog 的参数值, 则为这两个队列之和的最大值.
- Linux 2.2 之后的版本.
backlog指定了completely established队列的长度(即 ESTABLISHED), 而不是incomplement connection(即 SYN) 队列的长度. 在 Linux 中, 可以通过修改/proc/sys/net/ipv4/tcp_max_syn_backlog的值来修改SYN队列的长度大小. 也就意味着, 在现代的 Linux 系统中,SYN队列的长度是由操作系统级别来设置的, 而ESTABLISHED队列(也称为ACCEPT队列), 则是由应用程序来指定.
在Linux中, 如果收到一个三次握手的 ACK 数据包并且accept 队列已经满了, 它通常会忽略该数据包. 这听起来比较奇怪, 但记住, 有一个计时器与 SYN RECEIVED 状态相关: 如果没有收到 ACK 包(或者如果它被忽略, 如在这里考虑的情况), 那么 TCP 实现将重新发送 SYN / ACK 分组(具体是由 /proc/sys/net/ipv4/tcp_synack_retries指定尝试的次数)
但是, 如果开启(值为1, 目前为止, Linux 默认为0)了 /proc/sys/net/ipv4/tcp_abort_on_overflow 的话, 则会立即发送一个 RST 数据包给客户端.
cat /proc/sys/net/ipv4/tcp_synack_retries
2
cat /proc/sys/net/ipv4/tcp_max_syn_backlog
1024
cat /proc/sys/net/core/somaxconn
128
cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
设置 somaxconn 的值:
查看
sysctl -n net.core.somaxconn
设置
sudo sysctl -w net.core.somaxconn=1024
sudo sysctl -p
再次查看:
sysctl -n net.core.somaxconn
注意
如果设置了
syncookies为开启状态, 则系统会忽略/proc/sys/net/ipv4/tcp_max_syn_backlog设置的值, 理论上是变成无上限的.(好像现代的Linux, 都是开启了的~)查看: sysctl -n net.ipv4.tcp_syncookies 或 cat /proc/sys/net/ipv4/tcp_syncookies 设置: sudo echo 1 > /proc/sys/net/ipv4/tcp_syncookies 永久设置: vim /etc/sysctl.conf 添加或修改: net.ipv4.tcp_syncookies = 1 然后再执行以下命令 sudo sysctl -p如果应用层的
backlog参数大于/proc/sys/net/core/somaxconn中的值, 则自动截断为/proc/sys/net/core/somaxconn的数值. 这意味着, 实际的backlog大小为min(backlog, /proc/sys/net/core/somaxconn)的值.(通过man listen最后一部分可知)
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number o> f incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog. When syncookies are enabled there is no logical maximum length and this setting is ignored. See tcp(7) for more> information. If the backlog argument is greater than the value in /proc/sys/net/core/somaxconn, then it is silently truncated to that value; the default value in this file is 128. In kernels before 2.4.25, this l> imit was a hard coded value, SOMAXCONN, with the value 128.
Nginx 中的 backlog 设置
适当修改内核参数 net.core.somaxconn 大小, (如果设置超过了 512, 则也要修改 Nginx 的 listen 指令的 backlog 参数大小以匹配该参数)
net.core.netdev_max_backlog 在高带宽情况下, 可以调大该参数.
netdev_max_backlog
这个是网卡级别的 backlog 参数.
cat /proc/sys/net/core/netdev_max_backlog
1000
或
sysctl -n net.core.netdev_max_backlog
修改:
sudo sysctl -w net.core.netdev_max_backlog=2000
sudo sysctl -p
永久修改:
则修改 /etc/sysctl.conf 文件
命令行执行:
sudo sysctl -w net.core.netdev_max_backlog=2000; sudo sysctl -w net.core.somaxconn=65535
nginx 配置里修改:
listen 80 backlog=65535;
参考资料
TCP/IP协议中backlog参数 作者:Orgliny 出处:http://www.cnblogs.com/Orgliny 本文采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
man listen-
SO_SNDBUF和SO_RCVBUF
TCP 层
man 7 tcp
这两个是每个 socket 的读写缓冲区大小.
Linux 操作系统级别分别对应: 操作系统会在这范围内根据内存压力进行动态调整
读缓冲区, 也称为接收缓冲区(receive buffer)
cat /proc/sys/net/ipv4/tcp_rmem
4096 87380 6291456
上面三个数字, 分别表示 min, default, max.
min 的默认值为 PAGE_SIZE
default 的默认值, 由 net.core.rmem_default 来指定.
max: max(87380, min(4 MB, tcp_mem[1]*PAGE_SIZE/128))
写缓冲区, 也称为发送缓冲区(send buffer)
/proc/sys/net/ipv4/tcp_wmem
4096 16384 4194304
上面三个数字, 分别表示 min, default, max
min 的默认值为 PAGE_SIZE
default 的默认值, 由 net.core.wmem_default 来指定.
max: max(65536, min(4 MB, tcp_mem[1]*PAGE_SIZE/128))
注意, 操作系统上面的 min, max 并不是使用来限制 SO_SNDBUF 的大小的.
Socket 层
man 7 socket
SO_RCVBUF
Sets or gets the maximum socket receive buffer in bytes. The kernel doubles this value (to allow space for bookkeeping overhead) when it is set using setsockopt(2), and this doubled value is returned by getsockopt(2). The default value is set by the
/proc/sys/net/core/rmem_default file, and the maximum allowed value is set by the /proc/sys/net/core/rmem_max file. The minimum (doubled) value for this option is 256.
SO_SNDBUF
Sets or gets the maximum socket send buffer in bytes. The kernel doubles this value (to allow space for bookkeeping overhead) when it is set using setsockopt(2), and this doubled value is returned by getsockopt(2). The default value is set by the
/proc/sys/net/core/wmem_default file and the maximum allowed value is set by the /proc/sys/net/core/wmem_max file. The minimum (doubled) value for this option is 2048.
SO_REUSEADDR
man 7 socket 参考 SO_REUSEADDR 小节
Indicates that the rules used in validating addresses supplied in a bind(2) call should allow reuse of local addresses. For AF_INET sockets this means that a socket may bind, except when there is an active listening socket bound to the address. When
the listening socket is bound to INADDR_ANY with a specific port then it is not possible to bind to this port for any local address. Argument is an integer boolean flag
参考资料
- https://hea-www.harvard.edu/~fine/Tech/addrinuse.html
- http://www.cnblogs.com/mydomain/archive/2011/08/23/2150567.html
SO_TIMEOUT (应用层设置)
man 7 socket 参考 SO_RCVTIMEO and SO_SNDTIMEO 小节
SO_RCVTIMEO and SO_SNDTIMEO
Specify the receiving or sending timeouts until reporting an error. The argument is a struct timeval. If an input or output function blocks for this period of time, and data has been sent or received, the return value of that function will be the
amount of data transferred; if no data has been transferred and the timeout has been reached then -1 is returned with errno set to EAGAIN or EWOULDBLOCK, or EINPROGRESS (for connect(2)) just as if the socket was specified to be nonblocking. If the
timeout is set to zero (the default) then the operation will never timeout. Timeouts only have effect for system calls that perform socket I/O (e.g., read(2), recvmsg(2), send(2), sendmsg(2)); timeouts have no effect for select(2), poll(2),
epoll_wait(2), and so on.
SO_KEEPALIVE
man 7 socket 参考 SO_KEEPALIVE 小节
Enable sending of keep-alive messages on connection-oriented sockets. Expects an integer boolean flag.
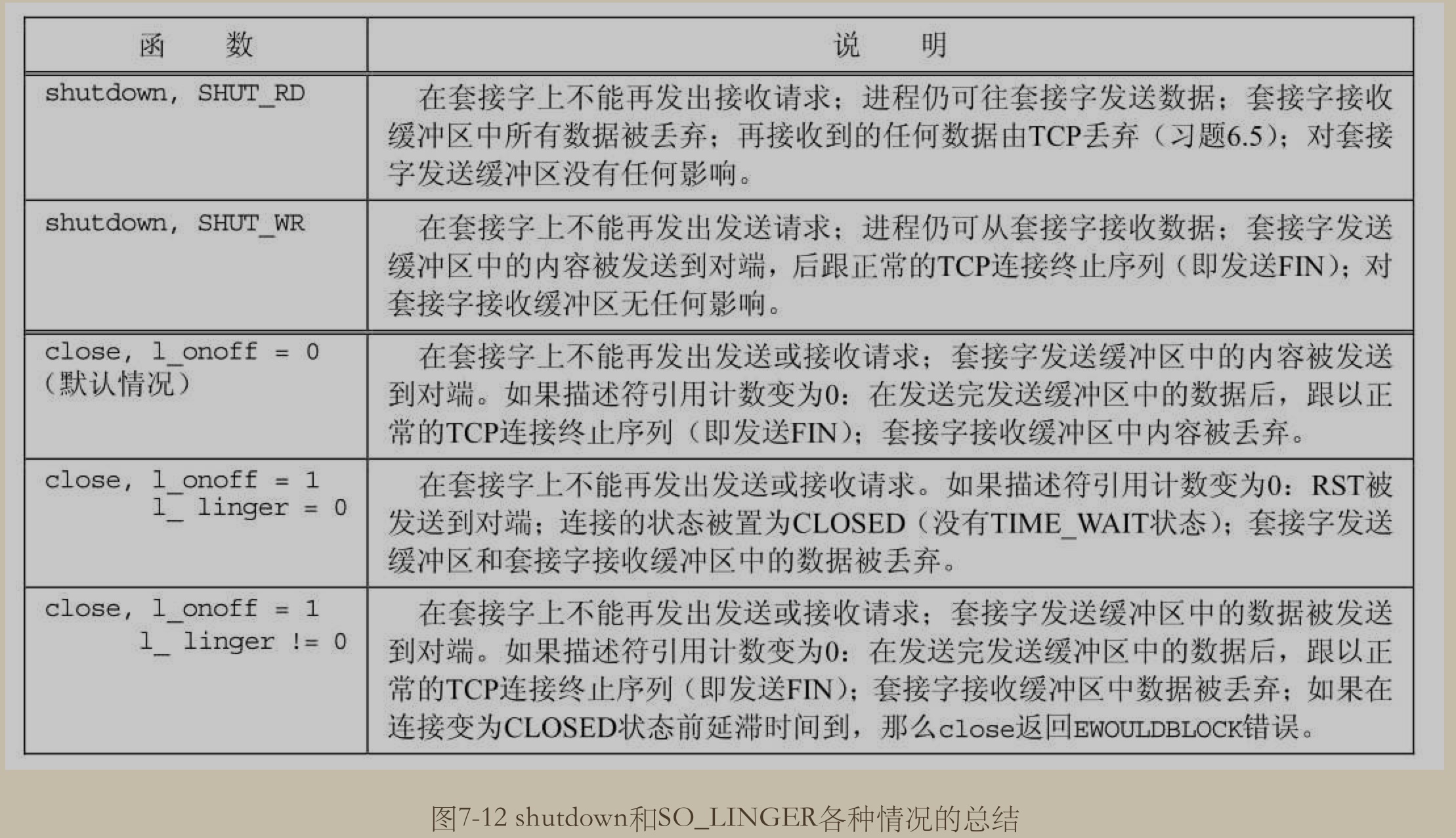
SO_LINGER 参数
man 7 socket 参考 SO_LINGER 小节
Sets or gets the SO_LINGER option. The argument is a linger structure.
struct linger {
int l_onoff; /* linger active */
int l_linger; /* how many seconds to linger for */
};
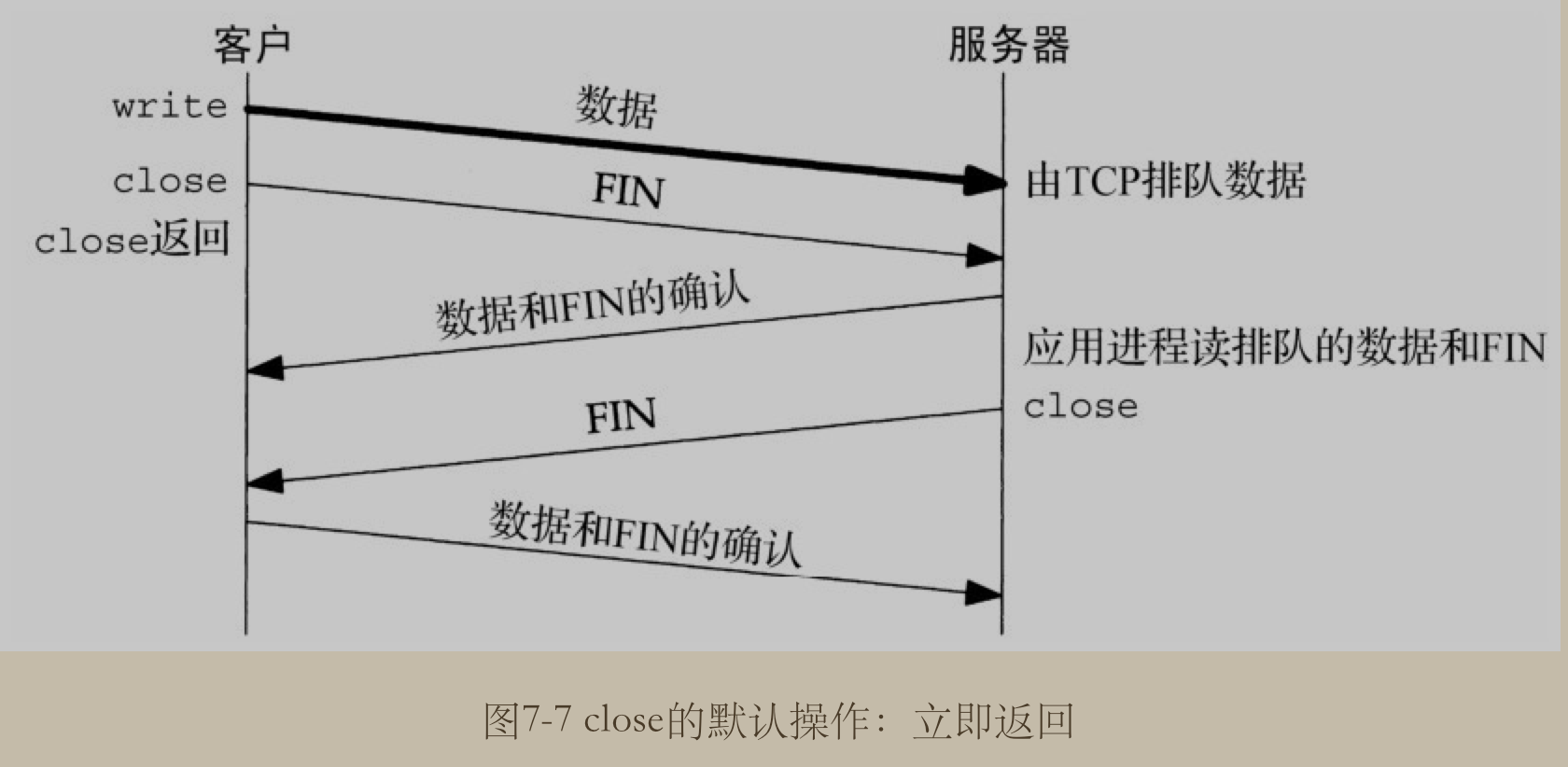
When enabled, a close(2) or shutdown(2) will not return until all queued messages for the socket have been successfully sent or the linger timeout has been reached. Otherwise, the call returns immediately and the closing is done in the background.
When the socket is closed as part of exit(2), it always lingers in the background.
即它是用来控制, 当在 socket 上调用 close 或 shutdown 方法时的行为. 如果开启了 linger , 则 socket 会在调用这两个方法完成之前一直等待socket 的队列消息已经全部成功发送或在 linger 超时时才返回.
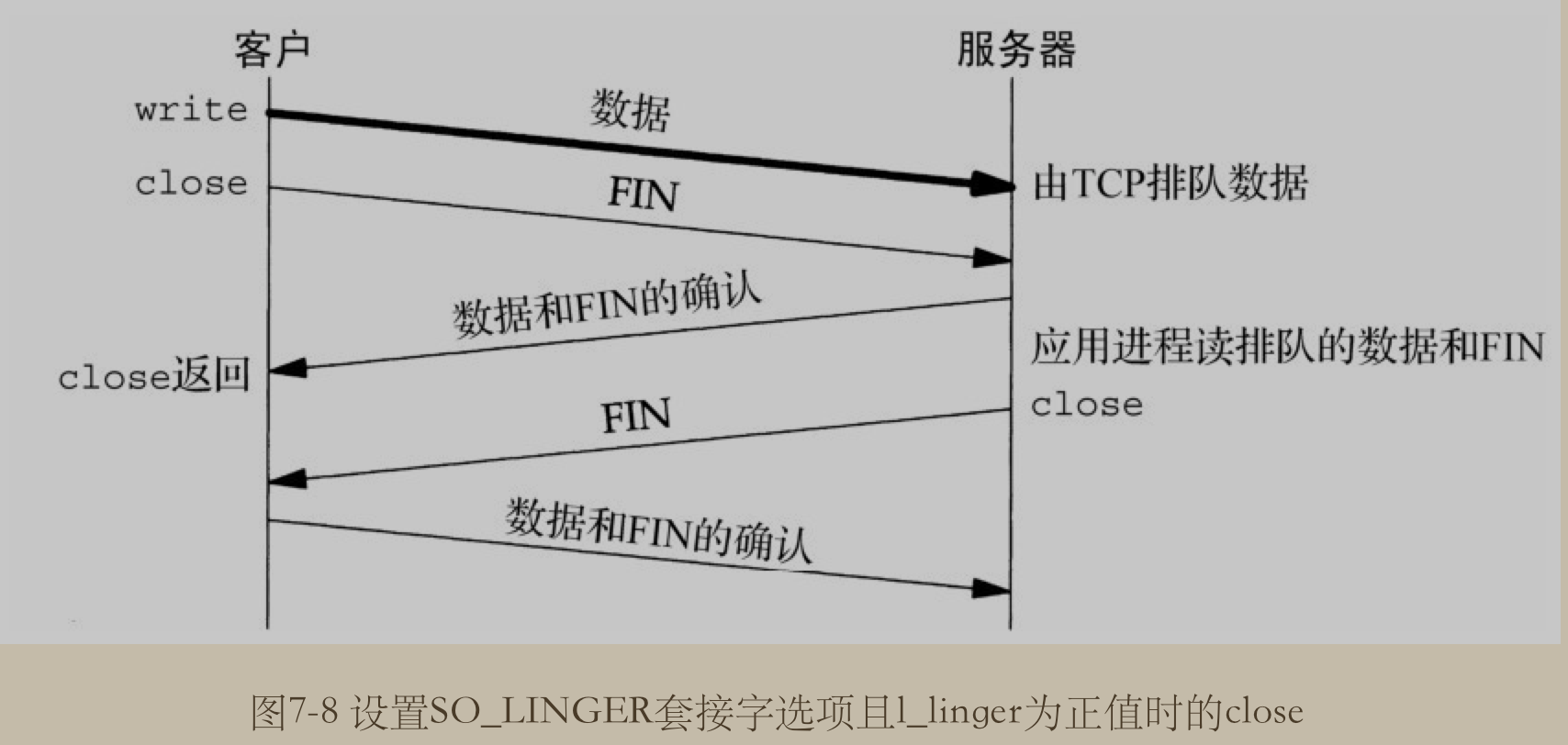
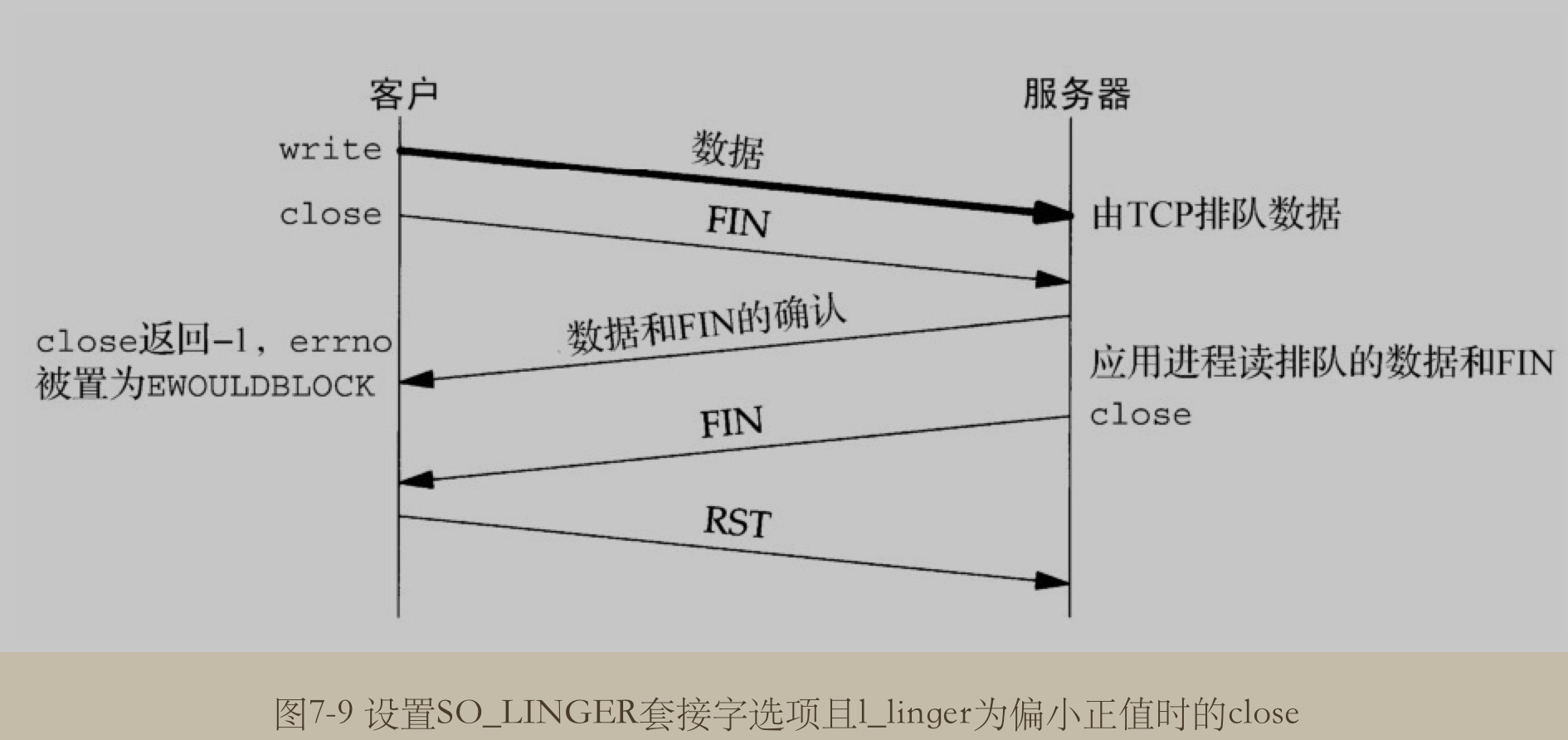
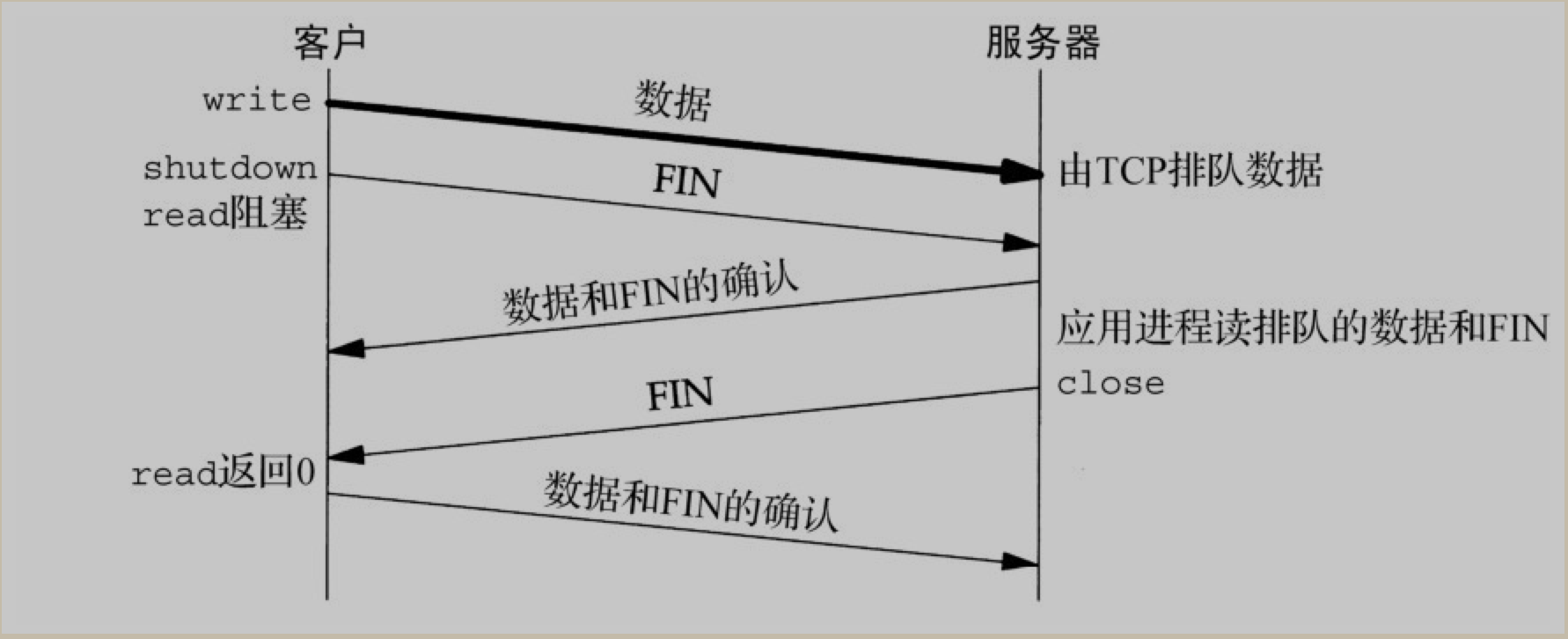
如果是关闭这个行为的话, 则调用这两个方法时, 立即关闭并返回.(这是默认的行为)
总结
Netty 中的 SO 前缀参数列表
public static final ChannelOption<Boolean> SO_BROADCAST = valueOf("SO_BROADCAST");
public static final ChannelOption<Boolean> SO_KEEPALIVE = valueOf("SO_KEEPALIVE");
public static final ChannelOption<Integer> SO_SNDBUF = valueOf("SO_SNDBUF");
public static final ChannelOption<Integer> SO_RCVBUF = valueOf("SO_RCVBUF");
public static final ChannelOption<Boolean> SO_REUSEADDR = valueOf("SO_REUSEADDR");
public static final ChannelOption<Integer> SO_LINGER = valueOf("SO_LINGER");
public static final ChannelOption<Integer> SO_BACKLOG = valueOf("SO_BACKLOG");
public static final ChannelOption<Integer> SO_TIMEOUT = valueOf("SO_TIMEOUT");
TCP 中的 TCP_NODELAY 参数
man 7 tcp
如果开启它的话(即为true或1), 表示禁止 TCP 的 Nagle 算法. 默认情况下, 该算法是启动的. 注意, 这个参数会被 TCP_CORK 参数覆盖, 但是, 即使设置了 TCP_CORK, TCP_NODELAY 参数也会强制显式地冲刷缓冲区.
TCP_NODELAY
If set, disable the Nagle algorithm. This means that segments are always sent as soon as possible, even if there is only a small amount of data. When not set, data is buffered until there is a sufficient amount to send out, thereby avoiding the fre‐
quent sending of small packets, which results in poor utilization of the network. This option is overridden by TCP_CORK; however, setting this option forces an explicit flush of pending output, even if TCP_CORK is currently set.
Nagle 算法
内容从
<Unix 网络编程>中摘录出来~
目的在于减少广域网WAN上小分组的数目. 该算法指出: 如果给定连接上有待确认数据(outstanding data), 那么原本应该作为用户写操作之响应的在该连接上立即发送相应小分组的行为就不会发生, 直到现有数据被确认为止. 这里的小分组的定义是小于 MSS (Max Segment Size) 的任何分组. TCP 总是尽可能地发送最大大小的分组, Nagle 算法的目的在于防止一个连接在任何时刻有多个小分组待确认.
与之联合使用的另一个算法为 ACK 延迟算法, delayed ACK algorithm, 该算法使得 TCP 在接收到数据后, 不立即发送ACK, 而是等待一小段时间(典型为 20~200ms), 然后才发送 ACK. TCP 期待在这小段时间内自身有数据发送回对端, 被延迟的ACK, 就可以由这些数据捎带, 从而省掉一个 TCP 分节.
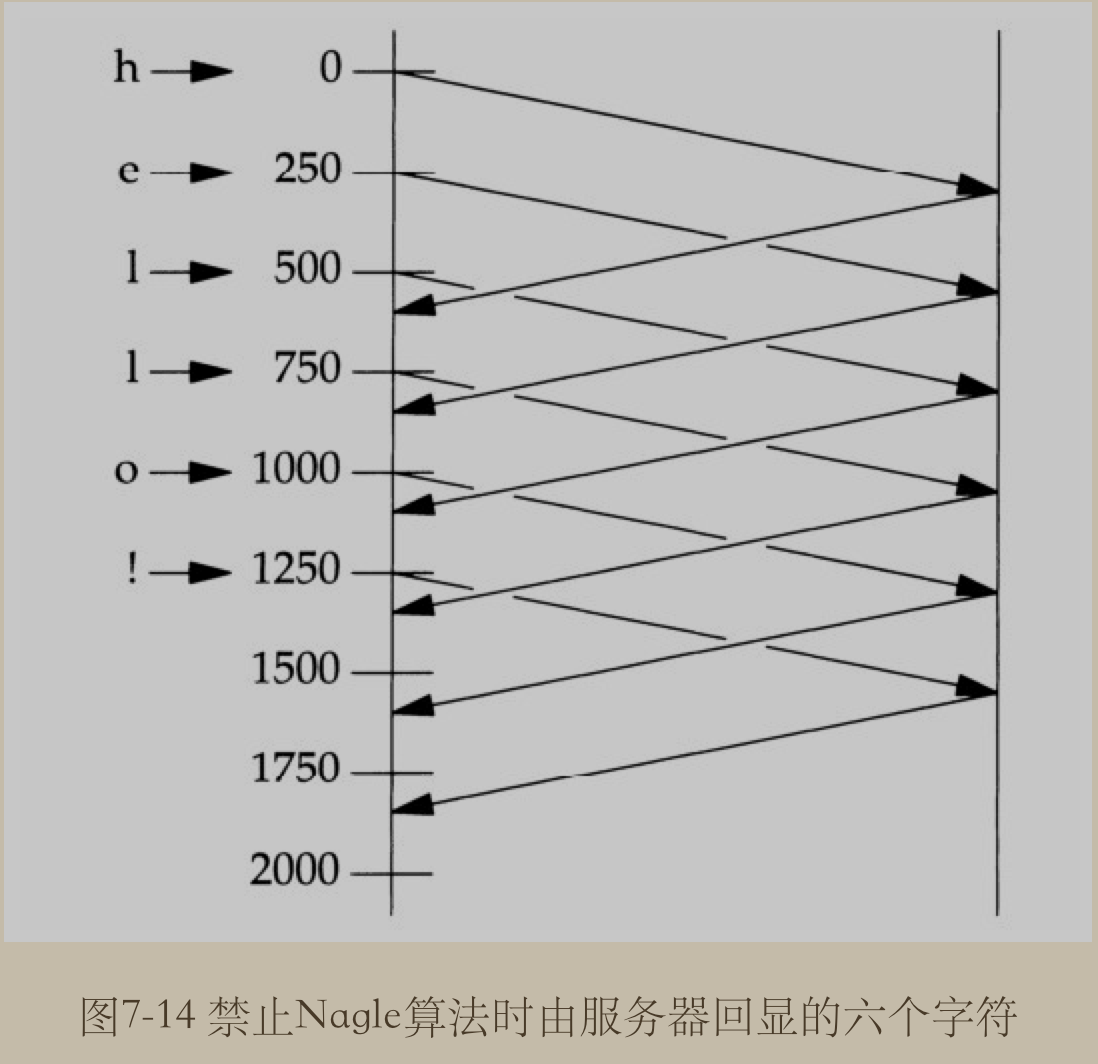
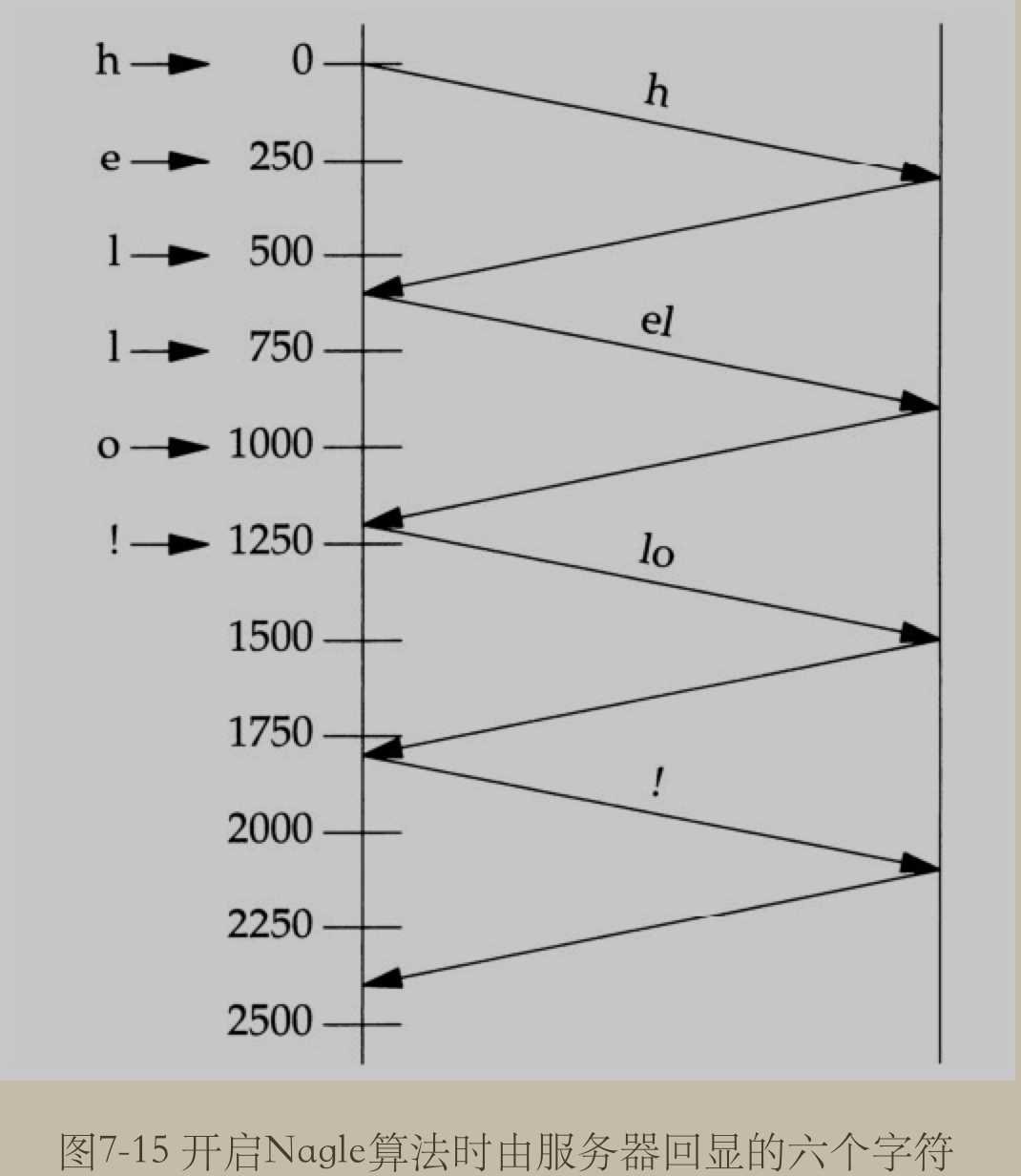
TCP_CORK 参数
Linux 2.2 开始
如果设置该参数, 表示不要发送部分分组(或叫分帧). 所有队列中的部分分组在清除该标志时会再次发送. 这对于在调用 sendfile(2) 之前预先确定头文件或用于吞吐量优化很有用. 按目前的实现, TCP_SORK 输出时间的上限为 200ms, 如果达到此上限, 则队列中的数据会自动进行传输. 自 Linux 2.5.71 以来, 这个选项只能与 TCP_NODELAY 结合使用.
If set, don't send out partial frames. All queued partial frames are sent when the option is cleared again. This is useful for prepending headers before calling sendfile(2), or for throughput optimization. As currently implemented, there is a 200
millisecond ceiling on the time for which output is corked by TCP_CORK. If this ceiling is reached, then queued data is automatically transmitted. This option can be combined with TCP_NODELAY only since Linux 2.5.71. This option should not be used
in code intended to be portable
Linux 内核参数 tcp_low_latency
tcp_low_latency (Boolean; default: disabled; since Linux 2.4.21/2.6)
If enabled, the TCP stack makes decisions that prefer lower latency as opposed to higher throughput. It this option is disabled, then higher throughput is preferred. An example of an application where this default should be changed would be a
Beowulf compute cluster
即 TCP 栈是否开启低延迟优先. (默认是关的, 即吞吐量优先).
cat /proc/sys/net/ipv4/tcp_low_latency
0