<Java 8 实战> 学习笔记
 times read
times read
Contents
流处理
流, 是一系列数据项, 一次只生成一项. 程序可以从输入流中一个一个读取数据项, 然后以同样的方式将数据项写入输出流. 一个程序的输出流, 很可能是另一个程序的输入流.
Java 8 可以透明地把输入的不相关部分拿到几个 CPU 内核上分别去执行你的 Stream 操作流水线 – 这是几乎免费的并行, 用不着费劲去搞 Thread 了.
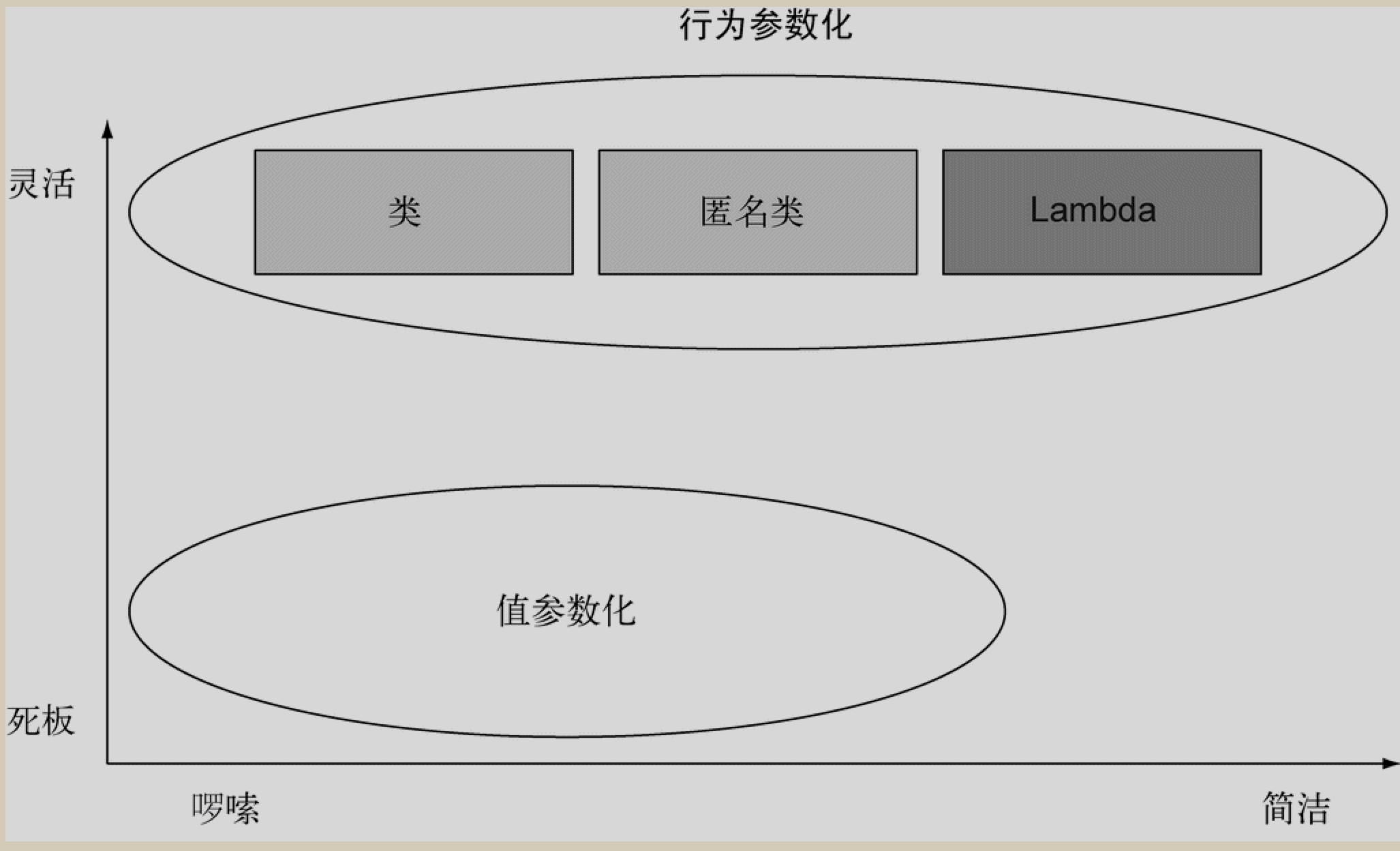
行为参数化
Java 8 增加了把方法作为参数传递给另一个方法的能力.
并行与共享的可变数据
上面说到的 “几乎免费并行” 的前提条件:
你的行为必须能够同时对不同的输入安全地执行.
这意味着你写代码时, 不能访问共享的可变数据. 这些函数有时称为 “纯函数” 或 “无副作用函数” 或 “无状态函数” .
函数式编程范式的基石
- 没有共享的可变数据
- 将方法和函数即代码, 传递给其他方法的能力
不能有共享的可变数据, 这意味着:
一个方法是可以通过它将参数值转换为结果的方式完全描述的; 换句话说, 它的行为就像一个数学函数, 没有可见的副作用.
命令式编程范式
写出的程序则是一系列状态的指令.
方法引用
类名::方法名 例如 :
new File(".").listFiles(File::isHidden);
谓词
在数学上常常用来代表一个类似函数的东西, 它接受一个参数值, 并返回 true 或 false .
外部迭代 VS 内部迭代
外部迭代: 使用 for-each 循环一个一个去迭代元素, 然后再处理元素
内部迭代: 数据处理完全是在库内部进行的.
Collections 与 Stream
Collections 主要是为了存储和访问数据, 而 Stream 则主要用于描述对数据的计算.
Stream 允许并提倡并行处理一个 Stream 中的元素.
首先库 Stream 会负责分块, 即把大的流分成几个小的流, 以便并行处理.
其次, 流提供的这个几乎免费的并行, 只有在传递给 filter 之类的库方法的方法不会互动(比如说有可变的共享对象)时才能工作. 这一点要特别注意.
lamdba
语法:
(parameters) -> exprssion
或
(parameters) -> {statements;}

lamdba 用法
它可以用在函数式接口上.
函数式接口
就是只定义一个抽象方法的接口. 重点强调: 只能一个! (继承接口的多个抽象不算!), 并且这一个只能是抽象方法. (但可以有多个 default 默认实现的方法)
强烈建议在所有函数式接口上加上标注: @FunctionalInterface 这样子, 就会让编译器来检查了.
注意! 任何函数式接口都不允许抛出受检异常(checked exception).
函数描述符
函数式接口的抽象方法的签名基本上就是Lamdba表达式的签名. 这种抽象方法叫作函数描述符.
表示法:
() -> void 表示参数列表为空, 且返回void
(Apple, Appl) -> int 表示接受两个 Apple 作为参数且返回 int 的函数.
lamdba 与 原始类型的装箱
xxPredicate 的形式的函数式接口, 它避免了使用泛型(这种对原始类型的, 必须要进行装箱和解箱操作). 这就有非常大的不同了!
例如:
IntPredicate LongPredicate DoublePredicate
使用局部变量
lamdba 表达式允许使用 自由变量 (不是参数, 而是在外层作用域中定义的变量), 就像匿名类一样. 它们被称作捕获 Lamdba.
Lamdba 可以没有限制地捕获(也就是在主体中引用)实例变量和静态变量. 但局部变量必须显式声明为 final , 或事实上是 final . 换句话说, Lamdba 表达式只能捕获指派给它们局部变量一次.
例如这样子编译就没问题:
public static void main(String[] args) {
int hello = 10;
Runnable r = () -> System.out.println(hello);
r.run();
}
但下面这样子就不行:
public static void main(String[] args) {
int hello = 10;
Runnable r = () -> System.out.println(hello);
hello = 20;
r.run();
}
编译器会报:
java: local variables referenced from a lambda expression must be final or effectively final.
方法引用
可以被看作仅仅调用特定方法的 Lamdba 的一种快捷写法.例如
Apple::getWeight 就是引用了 Apple 类中定义的方法 getWeight . 它是Lamdba 表达式 (Apple a) -> a.getWeight() 的快捷写法.
Java 8 自带的函数式接口
java.util.function 包里
流 stream
流与集合的区别
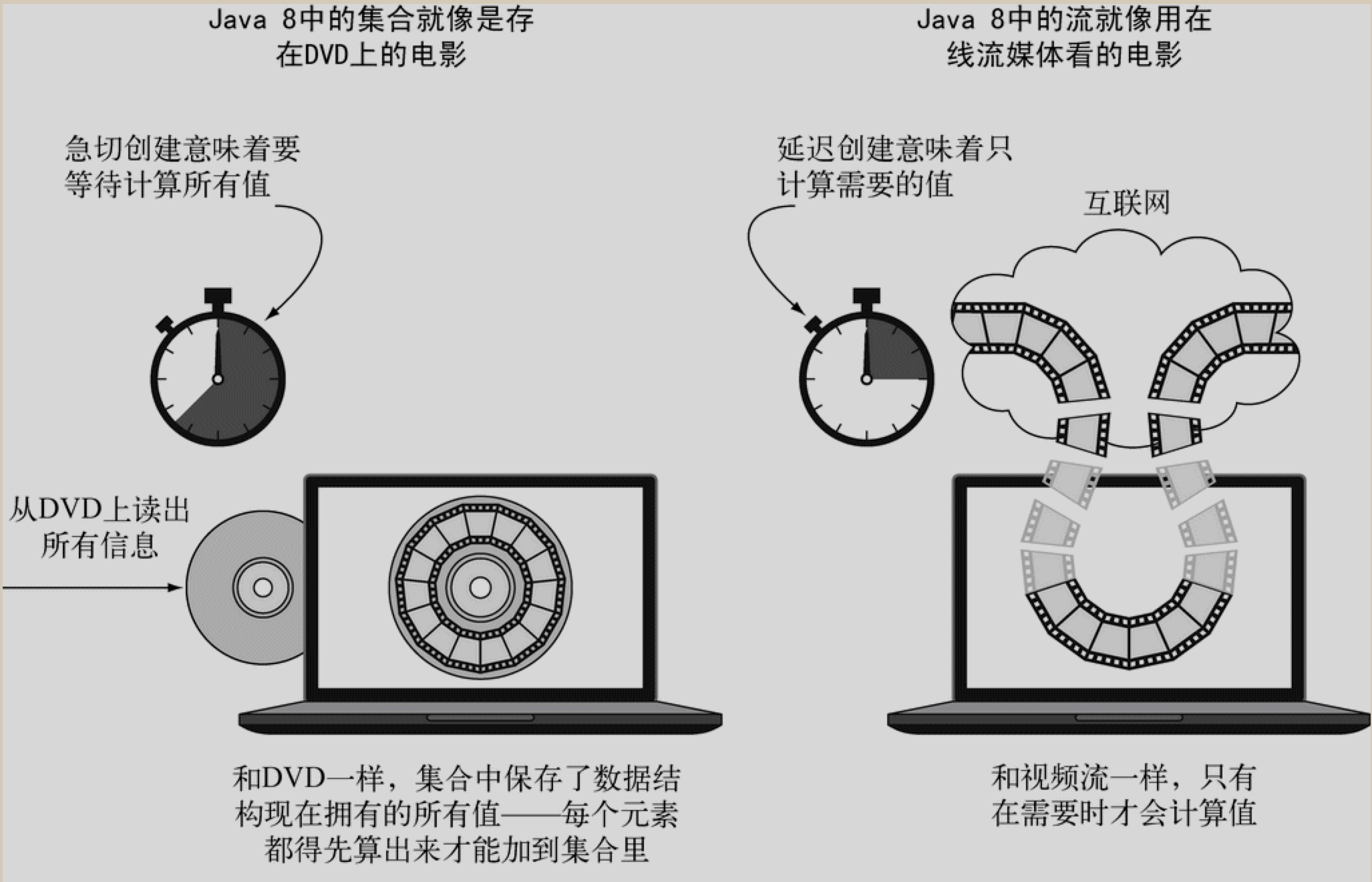
一个流只能遍历一次!
流的中间操作
- filter
- map
- limit
- sorted
- distinct
流的终端操作
- forEach
- count
- collect
流式处理
它是直接像流水线一样处理的, 而不是一步一步来处理的.
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4, 1, 3, 8, 9, 10, 3, 2, 10, 3, 2, 3, 4, 10, 20);
numbers.stream().filter(i -> {
System.out.println("filtering " + i);
return i % 2 == 0;
})
.distinct()
.forEach((e) -> {
System.out.println("in foreach" + e);
});
}
打印的结果
filtering 1
filtering 2
in foreach2
filtering 1
filtering 3
filtering 3
filtering 2
filtering 4
in foreach4
filtering 1
filtering 3
filtering 8
in foreach8
filtering 9
filtering 10
in foreach10
filtering 3
filtering 2
filtering 10
filtering 3
filtering 2
filtering 3
filtering 4
filtering 10
filtering 20
in foreach20
映射 map
它会接受一个函数作为参数. 这个函数会被应用到每个元素上, 并将其映射成一个新的元素(使用映射一词, 是因为它和转换类似, 但其中的细微差别在于它是 “创建一个新版本” 而不是去 “修改”).
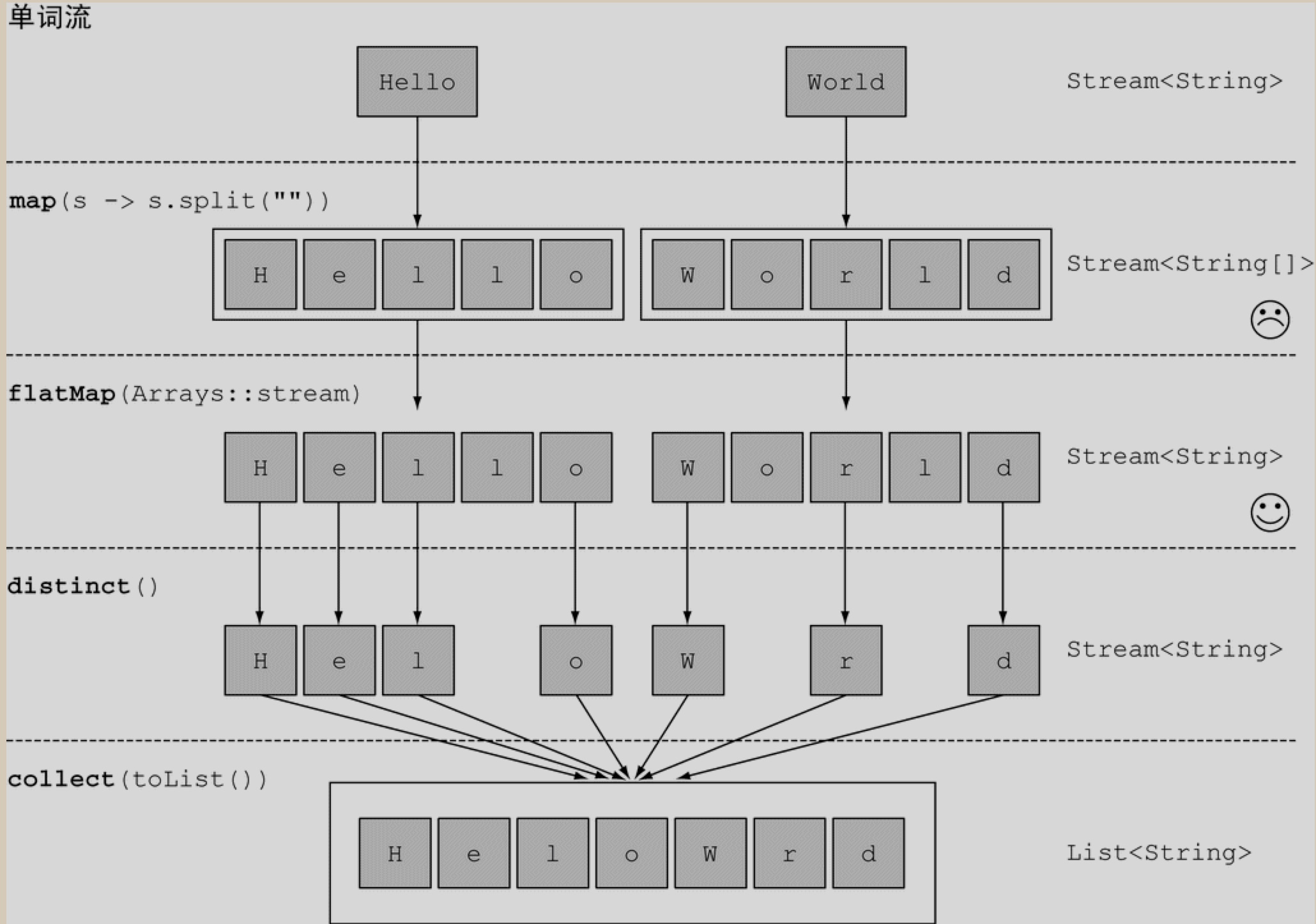
flatMap
它的效果是, 各个数组并不是分别映射成一个流, 而是映射成流的内容. 所有使用 map(Arrays::stream) 时生成的单个流都被合并起来, 即扁平为一个流. 换句话说, flatMap 让你把一个流中的每个值都换成另一个流, 然后把所有的流连接起来成为一个流.
示例图
查找元素
findFirst VS findAny , 它们会影响并行. findFirst 在并行上限制更多. 如果不关心返回的元素是哪个, 请用 findAny , 因为它在并行中限制较少.
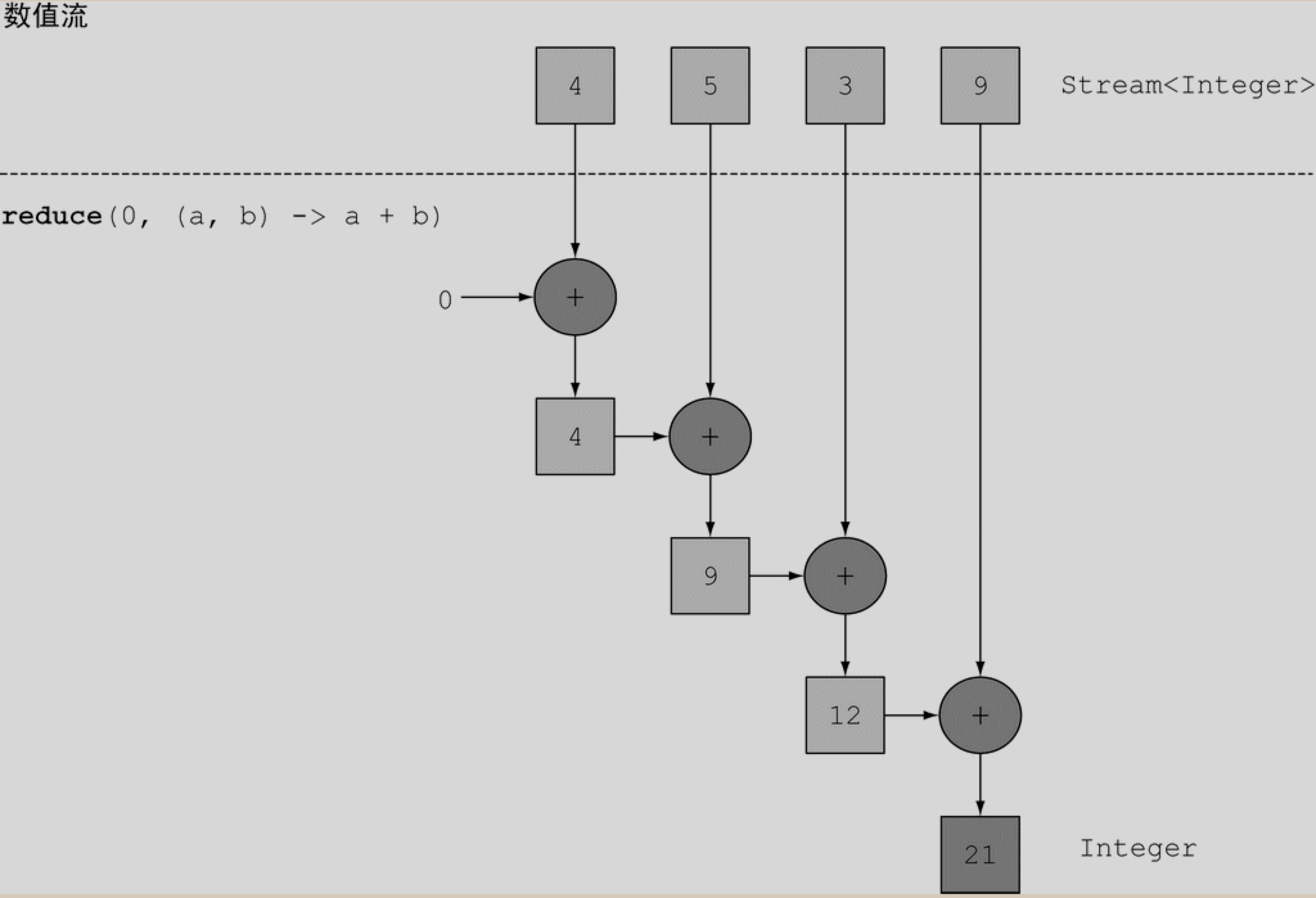
归约 reduce
将流中所有元素反复结合起来得到一个值, 比如一个 Integer , 这样的查询可以被归类为归约操作(将流归约成一个值). 用函数式编程语言的术语来说, 这称为折叠(fold).
它接受两个参数
- 一个初始值(可选, 如果没初始值, 则返回一个 Optional 对象)
- 一个 BinaryOperation
来将两个元素结合起来产生一个新值.
示意图
构建流
由值创建流: Stream.of
由数组创建流: Arrays.stream
由文件生成流: Files 很多静态方法都会返回一个流, 如 Files.lines
同函数生成流: 创建无限流 => Stream.iterate 和 Stream.generate 一般来说, 应该使用 limit(n) 来对这种流加以限制.
并行处理数据
最后一次 parallel 或 sequential 调用会影响整个流水线.(以最后一次的为准)
内部原理
内部使用了默认的 ForkJoinPool (默认的线程数量就是你的处理器数量). Runtime.getRuntime().availableProcessors() . 可以通过系统属性来改变线程池大小:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "1.2");
除非有很好的理由, 否则强烈建议你不要修改它.
iterate 在本质上是顺序的!
正确使用并行流
错用并行流的首要原因: 算法改变了某些共享状态.
- 如有疑问, 测量! 并行流并不总是比顺序流快.
- 留意装箱. 自动装箱和拆箱会大大降低性能.
- 有些操作在并行流上的性能就比顺序流差. 特别是 limit 和 findFirst 等依赖于元素顺序的操作, 它们在并行流上执行的代价非常大.
- 考虑流的操作流水线的总计算成本. 设N是元素的总数, Q是一个元素通过流水线的处理成本, 则
N * Q总是粗略的定性估计. Q 值较高, 意味着使用并行流时性能好的可能性比较大. - 对于较小的数据量, 选择并行流几乎从来不是一个好的决定.并行处理几个元素的好处抵不上并行化造成的额外开销.
- 要考虑流背后的数据结构是否易于分解. 例如 ArrayList 的拆分效率比 LinkedList 高得多. 因为前者用不着遍历就可以平均拆分, 而后者则必须遍历.

- 流自身的特点, 以及流水线中的中间操作修改流的方式, 都可能会改变分解过程的性能. 例如一个 SIZED 流可以分成大小相等的两部分, 这样每个部分都可以比较高效地处理, 但筛选操作可能丢弃的元素个数却无法预测, 导致流本身大小未知.
- 还要考虑终端操作中合并步骤的代价是大是小(如 Collector 中的 combiner 方法). 如果这一步代价很大, 那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升.
Fork/Join 框架
目的是以递归方式将可以并行的任务拆分为更小的任务, 然后将每个子任务的结果合并起来生成整体结果. 它是 ExecutorService 接口的一个实现, 它把子任务分配给线程池(称为 ForkJoinPool) 中的工作线程.
RecursiveTask
线程池的任务必须是 RecursiveTask<R> 的一个子类, 其中R是并行化任务产生的结果类型. 如果不返回结果, 则是 RecursiveAction 类型.
Fork/Join 最佳做法
- 对一个任务调用 join 会阻塞调用方, 直到该任务做出结果. 因此, 有必要在两个子任务的计算都开始之后再调用它.
- 不应该在 RecursiveTask 内部使用 ForJoinPool 的 invoke 方法. 相反, 你应该始终直接调用 compute 或 fork 方法, 只有顺序代码才应该用 invoke 来启动并行计算.
- 对子任务调用 fork 方法可以把它排进 ForJoinPool. 同时对左边和右边的子任务调用它似乎很自然, 但这样做的效率要比直接对其中一个调用 compute 低. 这样做你可以为其中一个子任务重用同一线程, 从而避免在线程池中多分配一个任务造成开销.
- 调试比较麻烦.
- 和并行流一样, 你不应理所当然地认为在多核处理器上使用分支/合并框架就比顺序计算快.
Spliterator
它定义了并行流如何拆分它要遍历的数据. (比如并行统计字符, 我们要按单词来进行拆分?)
匿名类 VS Lamdba
- 匿名类和Lamdba 表达式中的 this 和 super 的含义是不同的! 匿名类中, this 代表的是类自身, 而 Lamdba 中, 它代表的是包含类.
- 匿名类可以屏蔽包含类的变量, 而 Lamdba 表达式不能(会导致编译错误)

默认方法
接口中可以添加默认方法.
用法:
- 可选方法
- 行为的多继承
解决冲突规则
- 类中的方法优先级最高. 类或父类中声明的方法的优先级高于任何声明为默认方法的优先级.
- 如果1无法判断, 则子接口的优先级更高: 函数签名相同时, 优先选择拥有最具体实现的默认方法的接口. 即如果 B 继承了 A, 那么 B 就比 A 更加具体.
- 最后, 如果还是无法判断, 继承了多个接口的类必须通过显式覆盖和调用期望的方法, 显式地选择使用哪一个默认方法的实现.
Optional VS null
创建 Optional 对象
- Optional.empty();
- Optional.of(T); // 如果 T 为 null 则也会抛NPE
- Optional.ofNullable(T); // 允许 T 为 null, 但不会抛 NPE
使用 map 从 optional 提取和转换值
optional.map(方法引用)
参考资料
Optional 中的 flatMap
flatMap方法与map方法类似,区别在于mapping函数的返回值不同。map方法的mapping函数返回值可以是任何类型T,而flatMap方法的mapping函数必须是Optional。
异步处理 Future 与 CompletableFuture
将同步API的调用封装到一个 CompletableFuture 中, 就能以异步的方式使用其结果.
新的日期 api
DateFormat 并不是线程安全的
这意味着两个线程如果尝试使用同一个 formatter 解析日期, 可能会得到无法预期的结果.
DateTimeFormatter
它是为了替代 DateFormat 的. 并且它是线程安全的!
LocalDate
不可变对象, 简单的日期, 并不含当天的时间信息.
要想修改, 则调用带有 withXXX 方法或 plusXXX, 它会返回对象的一个副本.
LocalTime
一天当中的时间信息.
LocalDateTime
LocalDate 与 LocalTime 的结合.