记录一次 MySQL 批量插入的优化

Contents
公司的DSP 项目,有个模块就是插入 RabbitMQ 里的 BID 的对象到 MySQL 然后再统计数据的业务. 但是, 发现这个 BID 批量插入的性能, 低得有点吓人. 平均 1K/s 的速度. 而这些日志, 每天有时可产生好几千 W 条 BID 的数据.
环境
MyBatis3.1 + Spring4.3.2 + shardbatis 分表插件
原因
本地测试时, 每次批量插入 1K 条数据性能:
bid insert time = 2506 ms
bid insert time = 2546 ms
bid insert time = 2632 ms
代码
初始版本代码
Java里的代码:
public int bidInsertBatch(List<TaskBidLog> logs, int userid) throws SQLException {
if (logs.size() > 0) {
return taskBidLogMapper.bidInsertBatch(logs, userid);
}
return 0;
}
Mapper 的 XML:
<insert id="bidInsertBatch">
insert into
task_bid_log
(
bid_id,
imp_id,
task_id,
bid_price,
win_price,
is_won,
age,
gender,
location,
con_type,
os,
osv,
brand,
geo,
ip,
idfa,
wax_user_id,
create_time,
update_time
)
values
<foreach collection="list" item="log" separator="," index="index">
(
#{log.bidId},
#{log.impId},
#{log.taskId},
#{log.bidPrice},
#{log.winPrice},
#{log.isWon},
#{log.age},
#{log.gender},
#{log.location},
#{log.conType},
#{log.os},
#{log.osv},
LEFT(#{log.brand}, 64),
#{log.geo},
#{log.ip},
#{log.idfa},
#{log.waxUserid},
#{log.createTime},
#{log.updateTime}
)
</foreach>
ON DUPLICATE KEY UPDATE
bid_price = values(bid_price),
age = values(age),
gender = values(gender),
location = values(location),
con_type = values(con_type),
os = values(os),
osv = values(osv),
brand = values(brand),
ip = values(ip),
idfa = values(idfa),
wax_user_id = values(wax_user_id),
create_time = values(create_time)
</insert>
记录实际执行时间
JDBC 的连接信息
mysql connector configuration properties
看官方文档, 可以看到可以记录 SQL 实际执行的各种时间, 即在 JDBC 的连接 URL 上加上如下代码:
profileSQL=true&gatherPerfMetrics=true&reportMetricsIntervalMillis=500&
jdbc:mysql://10.0.0.40:3308/unidsp?profileSQL=true&gatherPerfMetrics=true&reportMetricsIntervalMillis=500&useUnicode=true&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&characterEncoding=UTF-8
调试结果:

结果数据分析耗时及结论:
51 ms execute,
45 ms commit,
1590 ms : mapper 那条语句 (这里包括上面两个时间了)
1664ms 是整个方法
在 MySQL 客户端操作
用 root 用户登录 MySQL, 然后使用 show full process list 命令捕获线程执行的完整 SQL, 然后再在客户端直接执行, 发现执行的时间是119 ms:

这个与上面的 51 ms execute, 45 ms commit 这个记录的数据很接近了.
所以, 可以排除是 DB 服务自身的问题, 而是在 Java 代码层出现了问题.
使用原生的 JDBC 来操作
Java代码:
String sql = "insert into task_bid_log_2 (bid_id,imp_id,task_id,bid_price,win_price,is_won,age, gender,location,con_type,os,osv,brand,geo,ip,idfa,wax_user_id,create_time,update_time) values (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?) ON DUPLICATE KEY UPDATE bid_price = values(bid_price),age = values(age),gender = values(gender),location = values(location),con_type = values(con_type),os = values(os),osv = values(osv),brand = values(brand),ip = values(ip),idfa = values(idfa),wax_user_id = values(wax_user_id),create_time = values(create_time)";
PreparedStatement pstmt = connection.prepareStatement(sql);
for (TaskBidLog log : logs) {
pstmt.setString(1, log.getBidId());
pstmt.setString(2, log.getImpId());
pstmt.setString(3, log.getTaskId());
pstmt.setInt(4, log.getBidPrice());
pstmt.setInt(5, log.getWinPrice());
pstmt.setInt(6, log.getIsWon());
pstmt.setInt(7, log.getAge());
pstmt.setString(8, log.getGender());
pstmt.setString(9, log.getLocation());
pstmt.setString(10, log.getConType());
pstmt.setString(11, log.getOs());
pstmt.setString(12, log.getOsv());
pstmt.setString(13, log.getBrand());
pstmt.setString(14, log.getGeo());
pstmt.setString(15, log.getIp());
pstmt.setString(16, log.getIdfa());
pstmt.setString(17, log.getWaxUserid());
pstmt.setTimestamp(18, new Timestamp(log.getCreateTime().getTime()));
pstmt.setTimestamp(19, new Timestamp(log.getUpdateTime().getTime()));
pstmt.addBatch();
}
// Execute the batch
int [] updateCounts = pstmt.executeBatch();
System.out.append("inserted "+updateCounts.length);
执行情况跟踪(按上面的 JDBC 连接上加上那些记录时间的参数)

!!!惊呆了, 发现批量执行时, 它是每一条 SQL 发送一次给 MySQL 服务器的. 导致整个耗时为 47058ms, 即 47.058 秒了…
查了下资料, 这种情况下, 还要修改 JDBC 连接的 URL 的参数, 即加上以下参数:
useServerPrepStmts=false&rewriteBatchedStatements=true&useCompression=true
这时, 可以看到整个耗时为:

只要191 ms了.
使用 Mybatis + 事件循环插入
Java 代码:
@Transactional
public int bidInsertBatch(List<TaskBidLog> logs, int userid) throws SQLException {
int rs = 0;
for (TaskBidLog log : logs) {
rs += taskBidLogMapper.insert(log, userid);
}
return rs;
}
这种耗时, 也是非常久的. 通过按上面的参数的跟踪发送 SQL 的情况下发现, 虽然整体是一个事务, 但是 SQL 上, 是每一条 SQL 发送一次给 MySQL 服务器的.最后统一提交事务的.
加不加以下参数, 都是一样的:
useServerPrepStmts=false&rewriteBatchedStatements=true&useCompression=true
MyBatis 的问题
经过同事在另一边的 debug, 发现 MyBatis 在解析大量SQL 的时候, 耗时非常严重.
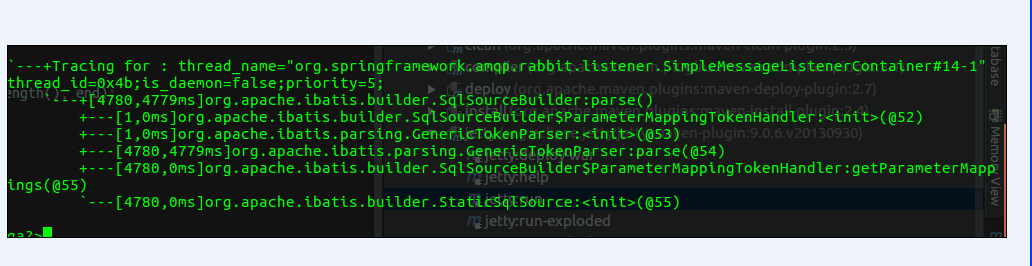
看来 Mybatis 并不是我们想像中的那样完美.
MyBatis 解析 SQL
解析 XML 里的语句得到 originalSql, 以及参数的类型 Class<?> parameterType, 这时得到的是带有#{xxx}类似的 SQL 的语句, 然后 MyBatis 再将#{} 替换为?,
最后再将parameterType 的值替换到? 所对应的位置里.
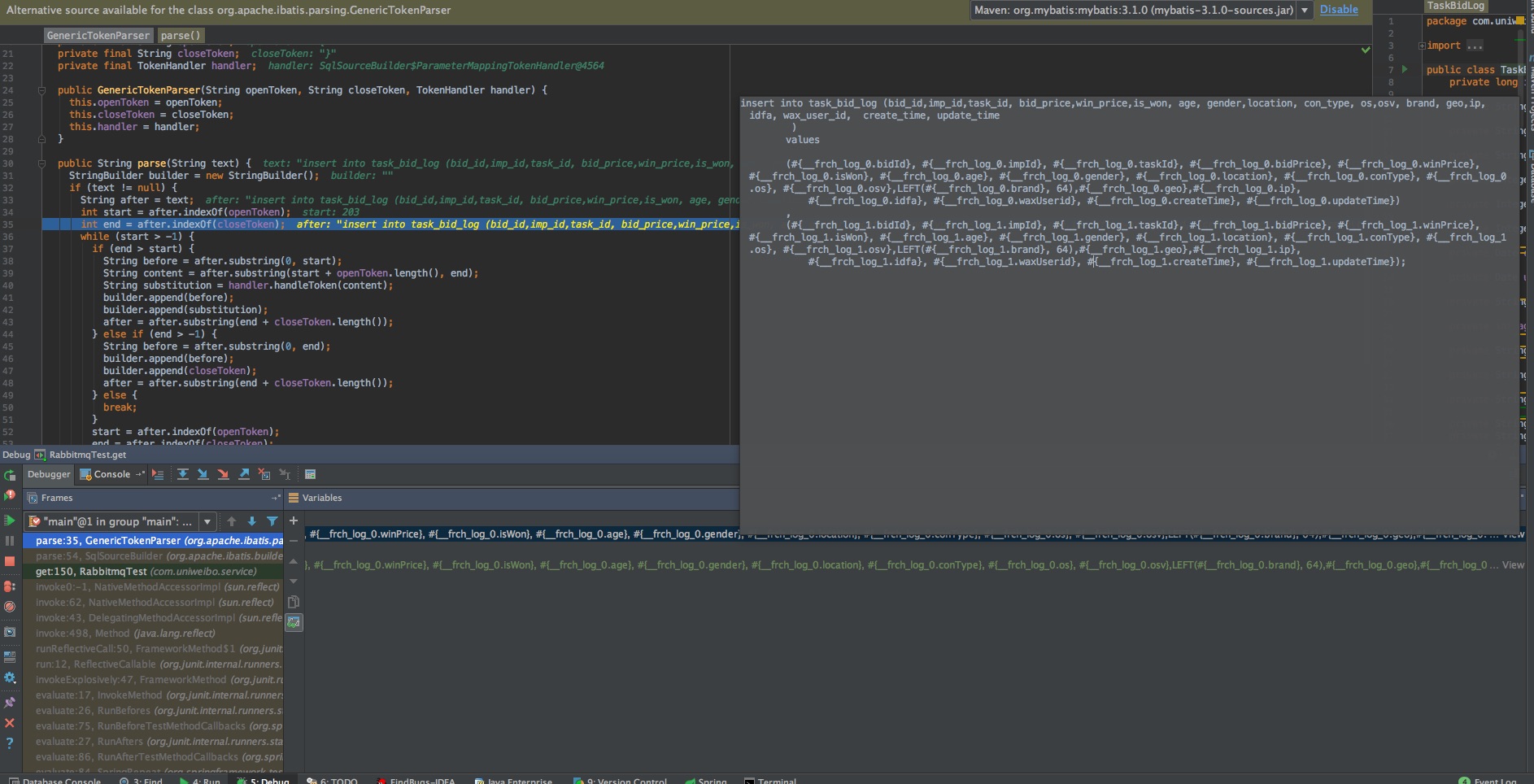
将#{}替换为?, 结果如下:
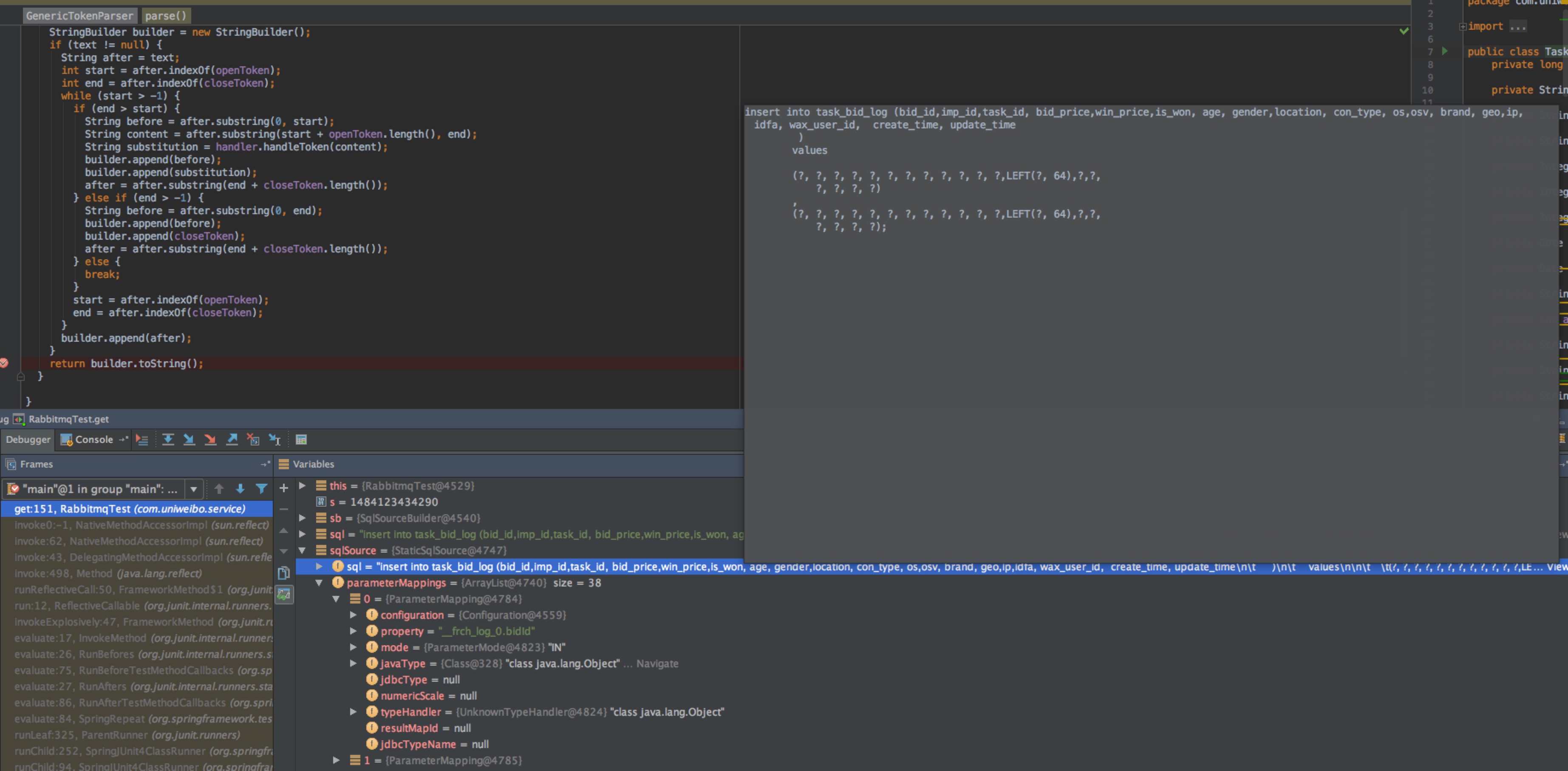
就是这解析的步骤, 在批量大的时候, 性能是非常低的…
总结
批量插入的情况下, 最理想的速度经测试, 应该是JDBC + executeBatch + JDBC url 加上参数 : useServerPrepStmts=false&rewriteBatchedStatements=true&useCompression=true