PostgreSQL执行计划和成本因子详解

Contents
PG对各表的统计信息:pg_stats
资源来源:PostgreSQL 9.3.1 中文文档 —— Chapter 47. 系统表 —— 47.68. pg_stats
名字 | 类型 | 引用 | 描述 :–|:–|:–| schemaname | name | pg_namespace.nspname | 包含此表的模式名字 tablename | name | pg_class.relname | 表的名字 attname | name | pg_attribute.attname | 这一行描述的字段的名字 inherited | bool | | 如果为真,那么这行包含继承的子字段,不只是指定表的值。 null_frac | real | | 记录中字段为空的百分比 avg_width | integer | | 字段记录以字节记的平均宽度 n_distinct | real | | 如果大于零,就是在字段中独立数值的估计数目。如果小于零, 就是独立数值的数目被行数除的负数。用负数形式是因为ANALYZE 认为独立数值的数目是随着表增长而增长; 正数的形式用于在字段看上去好像有固定的可能值数目的情况下。比如, -1 表示一个唯一字段,独立数值的个数和行数相同。 most_common_vals | anyarray | | 一个字段里最常用数值的列表。如果看上去没有啥数值比其它更常见,则为 null most_common_freqs | real[] | | 一个最常用数值的频率的列表,也就是说,每个出现的次数除以行数。 如果most_common_vals是 null ,则为 null。 histogram_bounds | anyarray | | 一个数值的列表,它把字段的数值分成几组大致相同热门的组。 如果在most_common_vals里有数值,则在这个饼图的计算中省略。 如果字段数据类型没有<操作符或者most_common_vals 列表代表了整个分布性,则这个字段为 null。 correlation | real | | 统计与字段值的物理行序和逻辑行序有关。它的范围从 -1 到 +1 。 在数值接近 -1 或者 +1 的时候,在字段上的索引扫描将被认为比它接近零的时候开销更少, 因为减少了对磁盘的随机访问。如果字段数据类型没有<操作符,那么这个字段为null。 most_common_elems | anyarray | | 经常在字段值中出现的非空元素值的列表。(标量类型为空。) most_common_elem_freqs | real[] | | 最常见元素值的频率列表,也就是,至少包含一个给定值的实例的行的分数。 每个元素频率跟着两到三个附加的值;它们是在每个元素频率之前的最小和最大值, 还有可选择的null元素的频率。(当most_common_elems 为null时,为null) elem_count_histogram | real[] | | 该字段中值的不同非空元素值的统计直方图,跟着不同非空元素的平均值。(标量类型为空。)
成本因子
因为PostgreSQL是基于代价模型来选择最优的执行计划的,而成本因子则是计算代价模型的最重要参数。(代价=CPU代价+IO代价+数据传输[如网络]代价)
在PG9.4默认情况下的成本因子如下:(这些值可以在 postgresql.conf 文件里修改的)
# - Planner Cost Constants -
#seq_page_cost = 1.0 # measured on an arbitrary scale。扫描一个数据块(一页)的成本(IO成本)
#random_page_cost = 4.0 # same scale as above。随机获取一个数据块(一页)的成本(IO成本)
#cpu_tuple_cost = 0.01 # same scale as above。获取一行数据的CPU成本
#cpu_index_tuple_cost = 0.005 # same scale as above。获取一个索引项的CPU成本
#cpu_operator_cost = 0.0025 # same scale as above。每个操作符的CPU成本
#effective_cache_size = 4GB #评估操作系统缓存可能使用的内存大小。用于评估索引扫描的开销,大的值倾向使用索引,小的值倾向使用全表扫描。一般设置为“物理内存 - shared buffers - 内核和其他软件占用的内存”。
注意:SSD的随机读和顺序读差别不是太大,这时可以缩小 seq_page_cost 和 random_page_cost 之间的大小。使random_page_cost趋向于seq_page_cost。
关于 effective_cache_size 特别说明一下
effective_cache_size用于在Linux操作系统上报告内核缓存的大小,我想强调一下它在postgresql.conf配置里的重要性。
effective_cache_size
不像其他内存那样是设置已经分配好的控制内存,effective_cache_size用于告诉优化器在内核里有多少cache(读缓存)。这对于决定代价高的索引扫描方式是非常重要的。优化器知道 shared_buffers 大小,但是不知道内核缓存大小,从而影响到代价非常高的磁盘访问。
内核缓存大小改变比较频繁,所以,正常地运行一段时间的系统负载,然后使用该内存值去设置 effective_cache_size。这个值不必是非常完美的,仅仅只是粗略地估计还有多少内核内存,相当于是shared buffers的二级缓存。
explain 输出及详解
explain 语法:
test=# \h explain;
Command: EXPLAIN
Description: show the execution plan of a statement
Syntax:
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
where option can be one of:
ANALYZE [ boolean ] 是否真正执行
VERBOSE [ boolean ] 显示详细信息
COSTS [ boolean ] 显示代价信息
BUFFERS [ boolean ] 显示缓存信息
TIMING [ boolean ] 显示时间信息
FORMAT { TEXT | XML | JSON | YAML } 输出格式,默认为 text
图解:
注意
看执行计划,是从最底层开始往后看的。即先从 节点1,再到节点2,最后到节点3。 而且,上一级节点的成本,是包含了下一级的成本的。比如:节点2的启动成本和结束成本是已经包含了节点1的启动成本和结束成本的,由此可以得出一个结论:就是上一级节点的启动成本和结束成本永远不会比下一级的小。
再次强调一下,每个节点的估算的总启动或结束成本只是平均每次loops的平均成本,所以最后的总成本还要乘以loops次数。
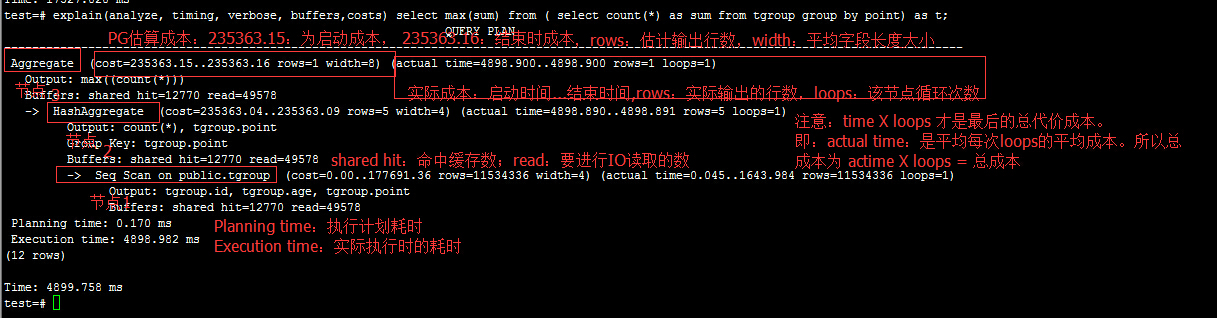
test=# explain(analyze, timing, verbose, buffers,costs) select max(sum) from ( select count(*) as sum from tgroup group by point) as t;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=235363.15..235363.16 rows=1 width=8) (actual time=4898.900..4898.900 rows=1 loops=1)
Output: max((count(*)))
Buffers: shared hit=12770 read=49578
-> HashAggregate (cost=235363.04..235363.09 rows=5 width=4) (actual time=4898.890..4898.891 rows=5 loops=1)
Output: count(*), tgroup.point
Group Key: tgroup.point
Buffers: shared hit=12770 read=49578
-> Seq Scan on public.tgroup (cost=0.00..177691.36 rows=11534336 width=4) (actual time=0.045..1643.984 rows=11534336 loops=1)
Output: tgroup.id, tgroup.age, tgroup.point
Buffers: shared hit=12770 read=49578
Planning time: 0.170 ms
Execution time: 4898.982 ms
(12 rows)
Time: 4899.758 ms
test=#
估算成本的计算公式
全表扫描时计算:
公式:total cost = relpages * seq_page_cost + reltuples * cpu_tuple_cost。
test=# select relpages, reltuples from pg_class where relname = 'tgroup';
-[ RECORD 1 ]----------
relpages | 62348
reltuples | 1.15343e+07
Time: 0.751 ms
test=# show seq_page_cost ;
-[ RECORD 1 ]-+--
seq_page_cost | 1
Time: 28.848 ms
test=# show cpu_tuple_cost;
-[ RECORD 1 ]--+-----
cpu_tuple_cost | 0.01
Time: 0.460 ms
如上节点1执行计划,是全表扫描:
177691.36 = 62348 * 1 + 1.15343e+07 * 0.01
test=# select 62348 * 1 + 1.15343e+07 * 0.01;
-[ RECORD 1 ]-------
?column? | 177691.00
Time: 39.815 ms
test=#
这个与结果相符。
全表顺序扫描并过滤,代价公式为:
Cost = seq_scan_cost*relpages + cpu_tuple_cost*reltuples + cpu_operator_cost*reltuples
扫描的方式
enable_bitmapscan = on
enable_hashagg = on
enable_hashjoin = on
enable_indexscan = on #索引扫描
enable_indexonlyscan = on #只读索引扫描
enable_material = on #物化视图
enable_mergejoin = on
enable_nestloop = on
enable_seqscan = on
enable_sort = on
enable_tidscan = on
虽然我们不能强制指定PostgreSQL按我们写的SQL来执行(无视优化器),但是可以通过改变某些的查询方式代价从而影响PostgreSQL的查询优化器的选择。
这时,我们可以从上面的扫描方式中将其修改为 off(其实不是强制不能以某种方式扫描,将其设置为 off时,只是将该项的扫描代价提高到非常大的值,从而让PostgreSQL尽可能避免使用该方式来进行扫描,但不是绝对的,如果其他的方式比off的代价更大,那PostgreSQL还是会选择代价最小的来执行的),这就为我们提供了非常好的控制我们SQL的扫描方式。
补充
如果explain,执行计划在同一层级,则是由上到下执行的的.
参考资料: